【事例付き】 BigQuery を活用したデータ分析基盤の構築方法を3ステップで解説!
- BigQuery
- DWH
- データ分析
本記事は、2021年9月7日に開催された Google の公式イベント「データクラウドサミット」において、弊社トップゲート開発部のエグゼクティブスペシャリストである鈴木達彦が講演した「 BigQuery で始める〜体験から学ぶデータ分析基盤構築の極意『3 Step 』〜」のレポート記事となります。
今回は、 BigQuery を活用したデータ分析基盤の構築方法を具体的な3ステップに分けてご説明します。 BigQuery の基本的な機能と使い方や Google Cloud (GCP)の各サービスとの連携、パイプラインの複雑化・本数増加への対策などを中心に詳しく解説します。ぜひ最後までご覧ください。
なお、本記事内で使用している画像に関しては、データクラウドサミット「 BigQuery で始める〜体験から学ぶデータ分析基盤構築の極意『3 Step 』〜」を出典元として参照しております。
それでは、早速内容を見ていきましょう。
目次
BigQuery によるデータ分析基盤の構築方法
BigQuery でデータ分析基盤を構築するためには、以下の3ステップを順番に進めていく必要があります。
- ステップ1.BigQuery の基本的な機能と使い方
- ステップ2.Google Cloud (GCP)の各サービスとの連携
- ステップ3.パイプラインの複雑化・本数増加への対策
まずは BigQuery の基本を理解し、小さく使い始めることでデータ基盤構築の第一歩を体験します。次に Google Cloud (GCP)の各サービスとの連携機能を活用し、 BigQuery へのデータ取り込み方式の選択肢や考慮事項を理解します。そして、最後にデータ基盤の拡張を見据えて、自社に適した対策を検討します。
この3ステップを順番に進めることで、データ分析基盤構築の基礎が身に付き、効率的に作業を進められるようになります。ポイントとしては、 BigQuery と Google Cloud (GCP)の機能や特性を体験して、段階的にデータ分析基盤の構想を広げていくことです。難しく考えすぎずに、まずは Google Cloud (GCP)に触れていくことが大切です。
ここから先は、各ステップについて具体的な内容をご説明します。
ステップ1.BigQuery の基本的な機能と使い方
まずは BigQuery の概要について理解しておきましょう。サービスの特徴や活用ケース、クエリ速度、費用などを順番にご説明します。
BigQuery とは?
BigQuery は TB (テラバイト)規模から数百 PB (ペタバイト)規模のデータを扱うようなお客様をサポートする、高性能なデータウェアハウスです。
BigQuery は Google Cloud (GCP)に内包されており、 100 % クラウドで提供されています。また、標準 SQL ( ANSI 2011 準拠)の DML をサポートしており、暗号化や高耐久性、高可用性などが特徴のサービスとなっています。
なお、 DML とは Data Manipulation Language (データ操作言語)の略であり、データベースを管理・操作するための言語を指しています。一般的なデータベースサービスでは、この DML でデータベースに記録された情報の参照や操作を行います。

BigQuery の活用ケース
BigQuery の活用ケースは多岐にわたりますが、今回は具体的な事例として、弊社トップゲート自身の活用事例を2つご紹介します。
広告レポート作成の自動化
従来は手動で広告レポート作成を行なっており、大きな手間と長い時間が掛かっていましたが、この業務を BigQuery で自動化しました。 BigQuery の活用により、結果として大きな費用削減に繋がった事例となっています。
データ分析にかかる時間の短縮
従来は社内のあらゆる場所からデータを手動で集約していたため、とても効率が悪く大きな工数が発生していました。このデータ集約を BigQuery で自動化した結果、データ分析における準備作業の期間を1ヶ月から1週間に短縮でき、大幅な効率化に成功しています。
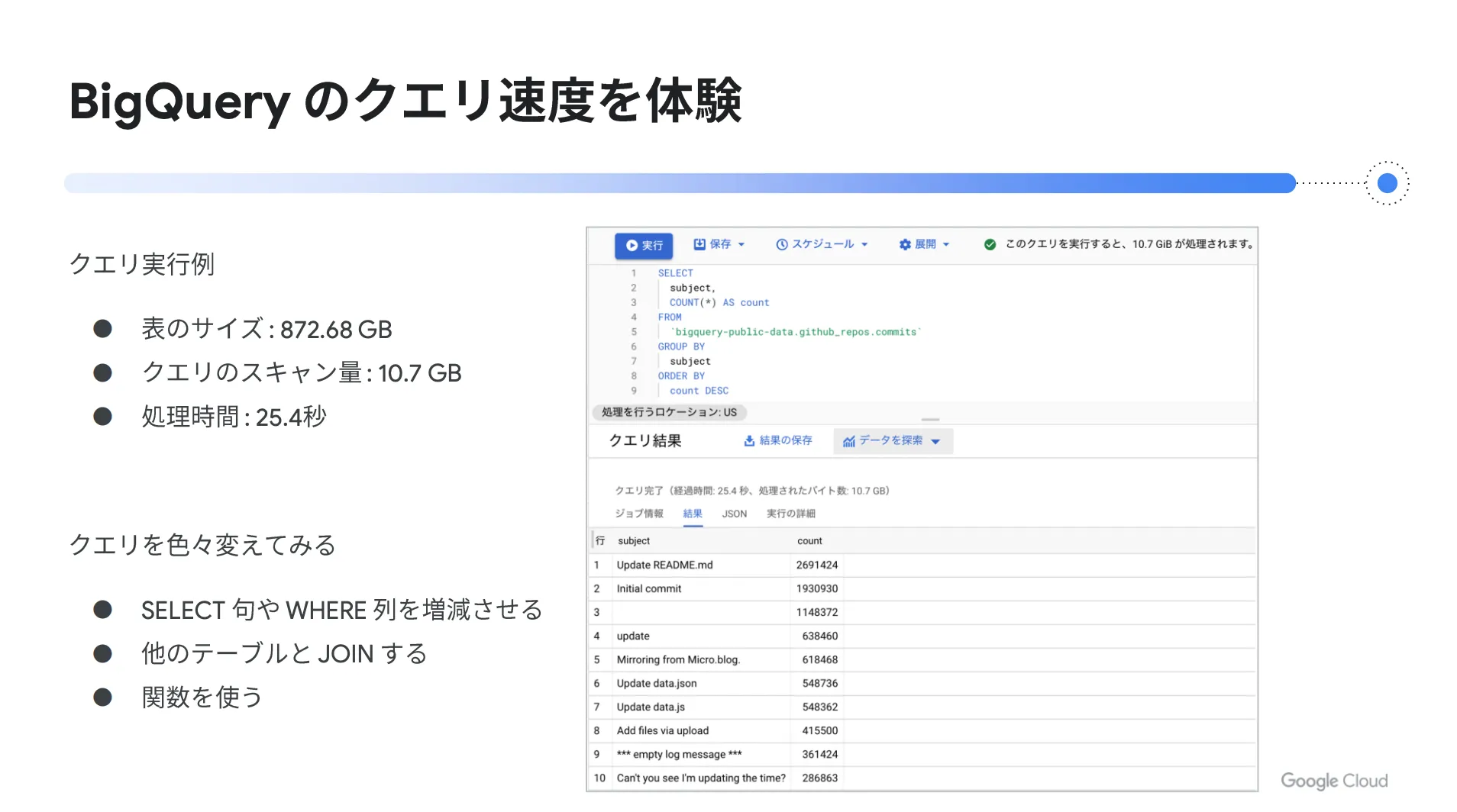
BigQuery のクエリ速度
BigQuery の大きな特徴として、超高速なクエリ速度が挙げられます。クエリ実行の一例として、表サイズ 32872.68 GB 、クエリスキャン量 10.7 GB の場合、クエリ完了までに要する時間は僅か25.4秒という結果でした。
また、 BigQuery を深く体感するためには、色々なクエリ作業を試してみることをオススメします。例えば、同じクエリを2回実行した場合、キャッシュが効いて処理時間が短くなり、バイト数がゼロになる機能もあります。
BigQuery の費用
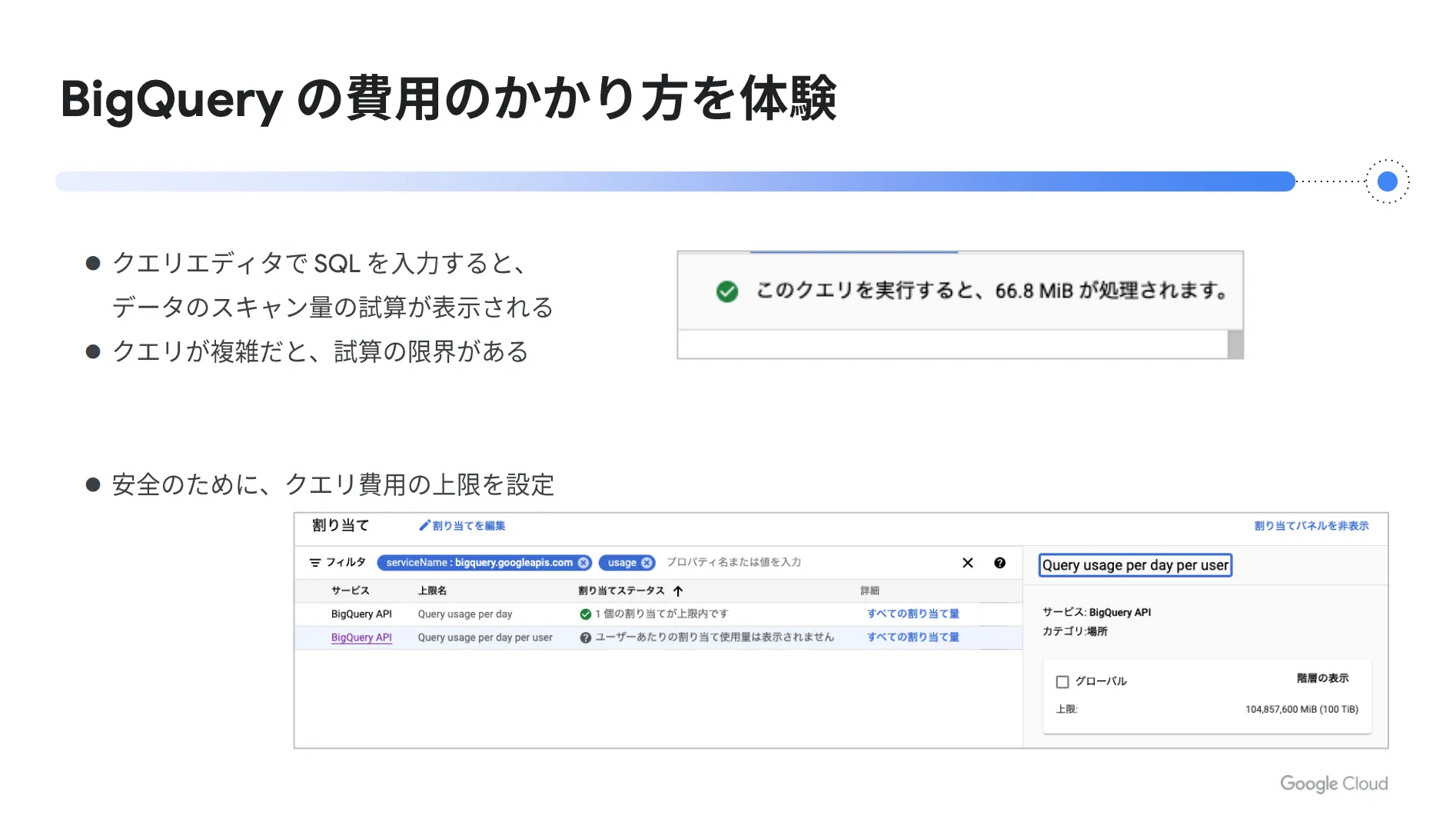
新しいサービスを利用する際は、かかる費用や料金体系を正しく理解することが大切です。この点を知らずに使用した場合、想定外の高額請求に繋がってしまうリスクがあります。
BigQuery はデータの保存量やクエリ実行時にスキャンするデータ量に応じて費用が発生します。クエリ実行時のスキャン量は事前に試算されるため、想定される金額を前もって把握することができます。
なお、試算には限界があるため、複雑なクエリを実行する場合は注意が必要です。高額課金が心配な方は、安全のためにクエリ費用の上限額を設定しておくことをオススメします。これにより、設定した金額以上の料金が発生することはありません。
初期データ基盤のスピード開発事例
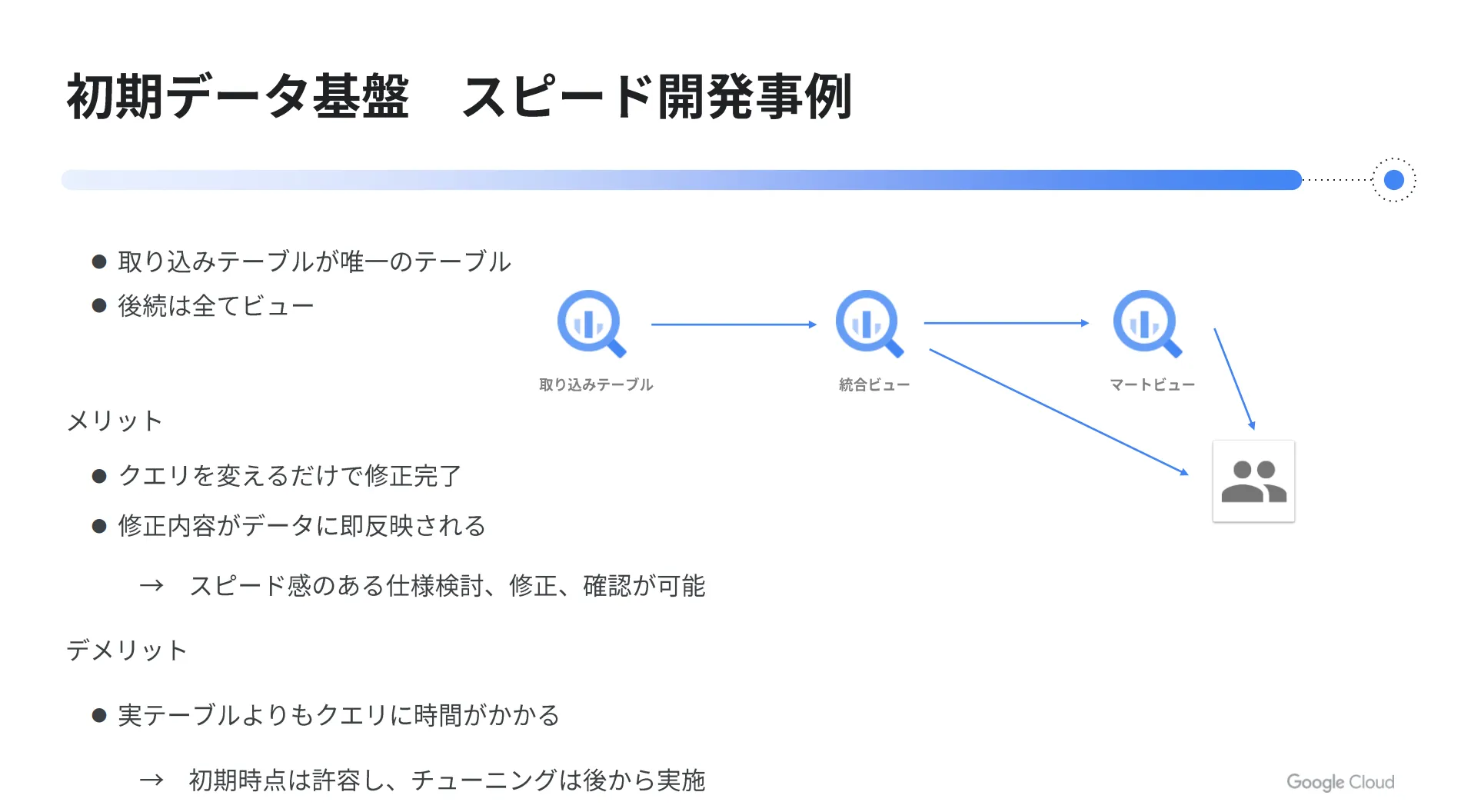
弊社トップゲートにおいて、初期データ基盤をスピード開発した事例をご紹介します。
この案件では、2〜3ヶ月でデータ基盤を早急に構築し、すぐに利用開始する必要がありました。そこで、 BigQuery にデータを取り込んだ後、加工や集計などの後続処理はテーブルではなく、ビューで作成する方法を採用しました。
この方法のメリットは、仕様変更などが発生した際に、ビューを定義している SQL を変えるだけで簡単に修正できる点です。これにより、下流のテーブル定義やデータの再作成などが不要になるため、スピード感をもって作業を進められるようになります。
ただし、実テーブルをクエリする場合と比較すれば、長い処理時間を要する点はデメリットになります。当時は頻繁にクエリを実行するような状況ではなかったため、初期時点はこの点を許容し、後からチューニングを行う形で開発を進めました。
BigQuery の関連記事をピックアップしました。関心のある方はぜひご覧ください。
超高速でデータ分析できる!専門知識なしで扱えるGoogle BigQueryがとにかくスゴイ!
ビッグデータの保存先はGoogle Cloudで決まり! BigQueryでデータを管理・分析のすすめ
【意外と簡単?】オンプレミスの DWH から BigQuery へのデータ移行を徹底解説!
BigQueryで考慮すべきセキュリティとその対策を一挙ご紹介!
ステップ2.Google Cloud (GCP)の各サービスとの連携
ここまでは BigQuery そのものに関するご説明をしましたが、 BigQuery は他の Google Cloud (GCP)の各サービスと連携することで、さらに便利に使うことができます。どのような連携方法があるのか、具体的に見ていきましょう。
Cloud Storage から BigQuery への取り込み
まずは Cloud Storage に置いてあるデータを BigQuery に自動で取り込む方法をご紹介します。大きく分けて2種類の方法があるので、それぞれ順番にご説明します。
一つ目は Cloud Storage の Pub / Sub 通知と Cloud Functions のイベントドリブン関数を利用する方法です。 Cloud Storage にファイルを置くと FINALIZE イベントが発生するため、このイベントを Pub / Sub に通知し、そこから Cloud Functions のイベントドリブン関数を起動するように設定します。
これにより、イベントドリブン関数が Cloud Storage から BigQuery へデータの取り込みを自動的にリクエストします。つまり、「ファイルが置かれた」というイベントを起点として、データの自動取り込みを実現できるのです。
二つ目は BigQuery Data Transfer Service を利用する方法です。 BigQuery Data Transfer Service を使うと、 Cloud Storage に置いてあるデータを任意のタイミングで自動的に BigQuery へ取り込むことができます。取り込み頻度は日次でスケジュール設定することも可能ですし、最小間隔15分ごとの単位で自由に決められます。

高頻度なデータ取り込みとログ分析
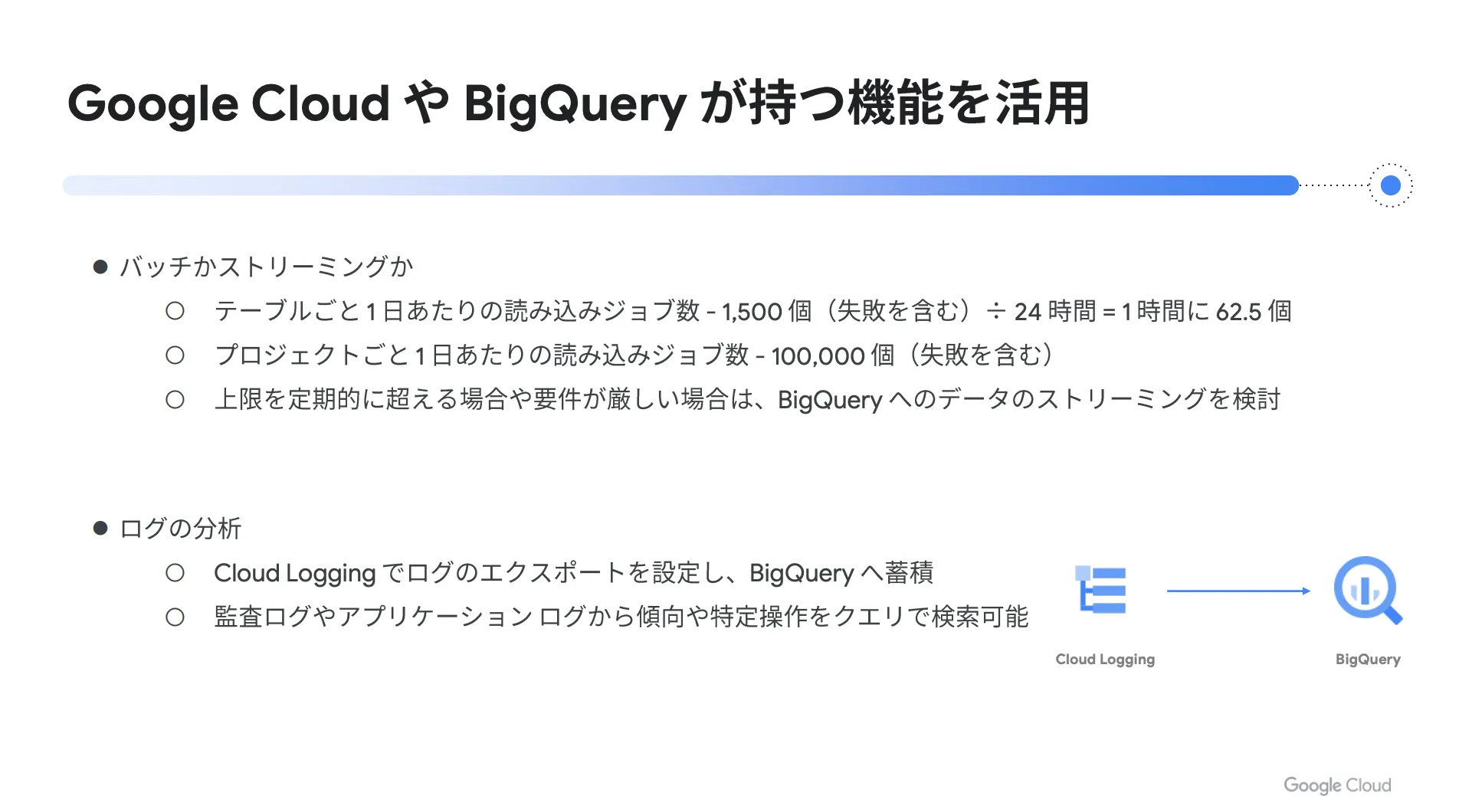
頻度の高いデータ取り込みを行う場合は、定期的なバッチ処理またはストリーミング処理の2つの選択肢がありますが、基本的な考え方としては、最初にバッチ処理で実現できるかどうかを確認するのがオススメです。
2021年9月現在の BigQuery の割り当て上限値を見ると、テーブルごとの1日あたりの読み込みジョブ数は1,500となっています。これを1日(24時間)で割り戻すと「1時間あたり約62.5個」という計算になります。つまり、1分ごとに1つのバッチ処理を実行できる、ということです。
また、テーブルではなくプロジェクト単位での読み込みジョブ数にも上限値が設定されており、1日あたり100,000となっています。仮に上限値を超えるほどの高頻度な処理が必要であったり、要件的にバッチ処理が難しかったりする場合は、 BigQuery のストリーミング処理を検討してください。
また、ログ分析を行う際は Cloud Logging でログのエクスポート設定を行うことで、 BigQuery にログを蓄積できます。 Cloud Logging のデフォルトではログの保持期間が決まっているため、長期間ログを保持しつつ BigQuery でログを検索できるような構成がオススメです。このログ検索においては、システムの傾向や特定操作などをクエリで検索可能になります。
クエリのスケジューリング
BigQuery にはクエリのスケジューリング機能が搭載されており、指定したタイミングでクエリを実行することが可能です。そのため、データを加工して、その結果を宛先のテーブルに書き込むような使い方ができます。このスケジューリング機能を利用する場合、担当者の異動や退職などが発生する可能性を考慮して、個人に依存しないサービスアカウントで認証を行うのがオススメです。
権限制御
権限制御はプロジェクトやデータセットの単位で設定することができます。プロジェクトで設定した場合、そのプロジェクトに含まれているすべてのデータセットに対して権限を設定することになります。また、テーブルや行、列など、より小さい単位で権限を設定することも可能ですが、細かくしすぎると権限設定が複雑になってしまうため、必要に応じて適宜利用する程度に留めておくと良いでしょう。
TIMESTAMP や DATETIME
日時に関するカラムはタイムゾーンに注意する必要があります。 BigQuery では、データセットがどのロケーションであっても、 TIMESTAMP のタイムゾーンは UTC になります。そのため、日本国内でデータ分析を行う場合は、分析データを作る時点で日本時間に変換し、 TIMESTAMP から DATETIME に変えて保存する運用が一般的です。
データパイプラインの構成イメージ
以下はデータパイプラインの構成イメージです。
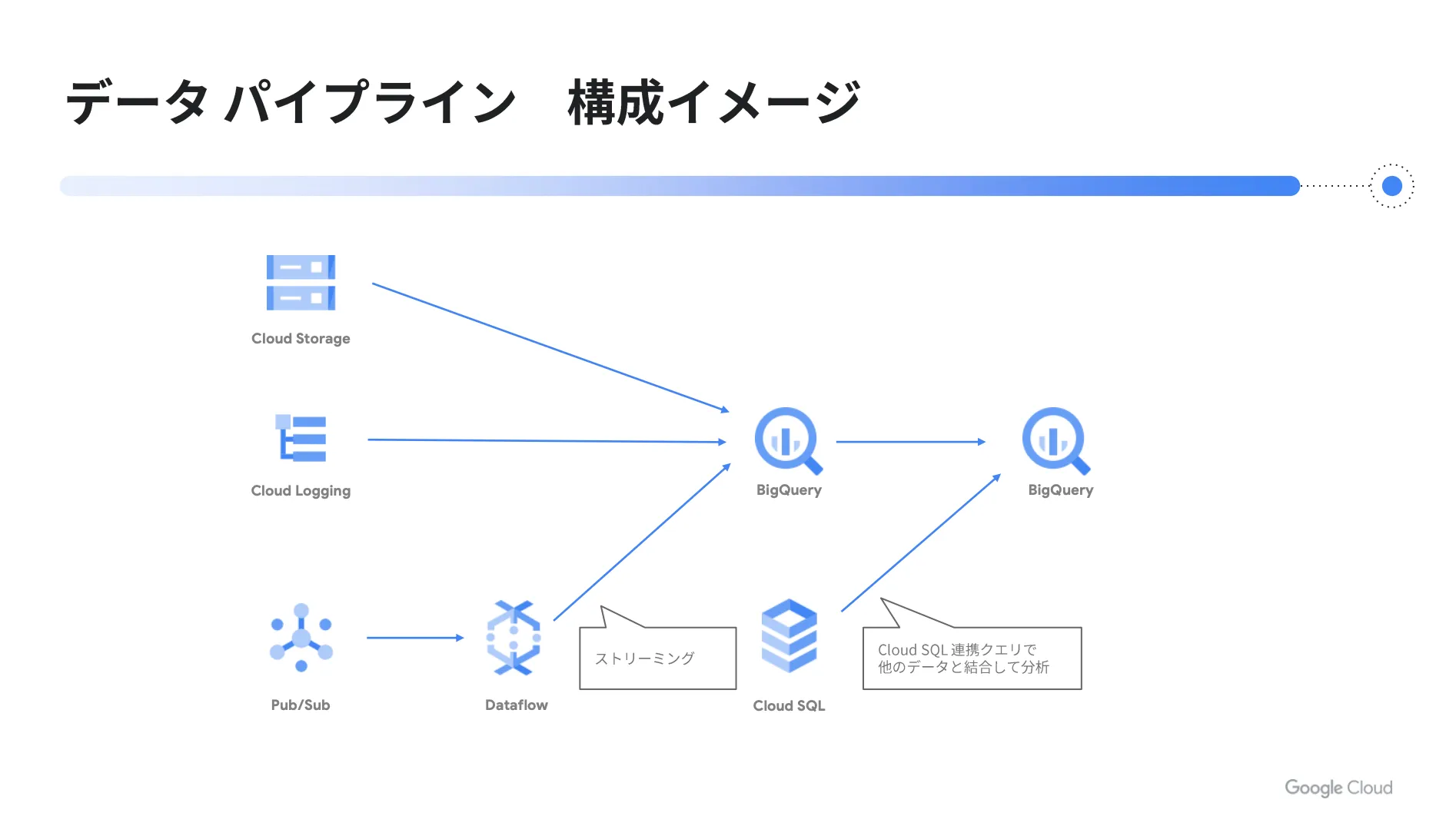
前述した Cloud Storage から BigQuery への取り込みや、 Cloud Logging から BigQuery への連携を視覚的にイメージできると思います。また、ストリーミング処理を行う場合には、 Pub / Sub でデータを受けて、 Dataflow で BigQuery へストリーミングを行います。
さらに、 BigQuery から BigQuery へ伸びている矢印については、 BigQuery に取り込んだデータをスケジューリングによって変換し、分析用のテーブルに書き込むような処理を意味しています。加えて、 Cloud SQL と BigQuery の間では、 Cloud SQL 連携クエリという機能が用意されており、 Cloud SQL の中に存在するデータを BigQuery のデータと一緒に合わせて分析することが可能になります。
これらの機能を活用して、データを分析するためのパイプラインを構築します。実際に図で見てみると、具体的なイメージが湧くのではないでしょうか?
データ送付パイプラインの開発事例
以下は弊社トップゲートにおけるデータ送付パイプラインの開発事例です。
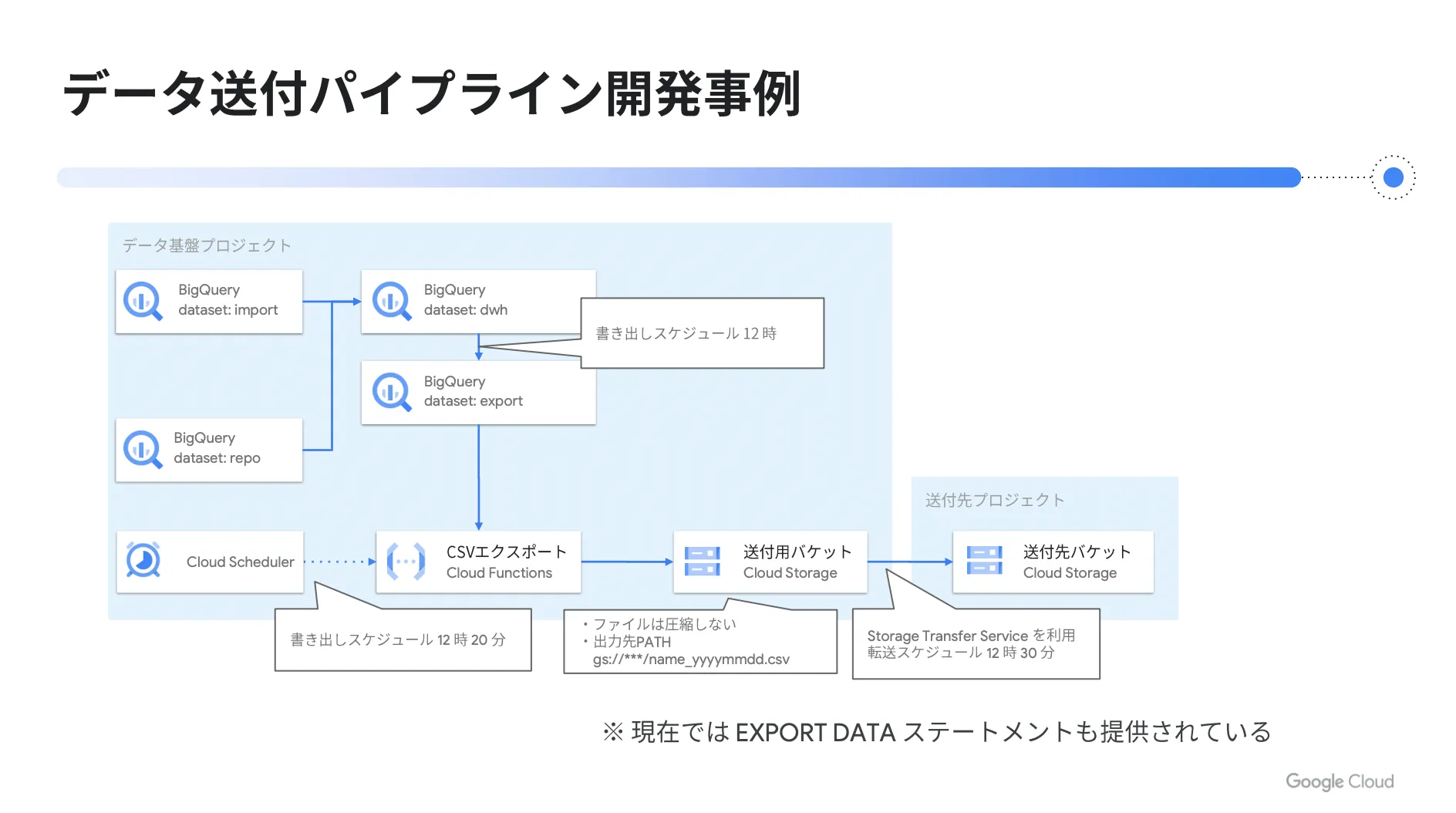
このパイプラインでは、 BigQuery から日次でデータをエクスポートして、別の送付先の Cloud Storage バケットへ配置する流れとなっています。図の中央上部にある DWH から、エクスポート用のテーブルをスケジュールクエリで作成し、 Cloud Scheduler で定期的に Cloud Functions を起動します。
この関数の中で、先ほど作成したテーブルをエクスポートし、 Cloud Storage へ保存します。そして、 Storage Transfer Service という機能を利用すれば、出力した Cloud Storage のバケットから送付先のバケットへ定期的に転送する仕組みを設定できるため、これを利用してデータを送付先のプロジェクトへ送ります。
開発当時は Cloud Functions を利用して BigQuery からデータをエクスポートしていましたが、現在はこの機能が BigQuery でも提供されており、 EXPORT DATA ステートメントを使ってクエリを実行することで、クエリ完了後に Cloud Storage へ自動的にデータをエクスポートできます。
これらの機能やサービスを活用すれば、簡単な設定だけでデータ送付を定期的に実行する仕組みを用意できるため、容易にパイプラインを構築することが可能になります。
ステップ3.パイプラインの複雑化・本数増加への対策
最後に、パイプラインの複雑化・本数増加への対策についてご説明します。
多くのチームがデータ基盤を利用している場合、利用者から様々な要望が出たり、システム制約が発生したりする可能性があります。また、連携元システムの影響を受けて、データパイプラインの処理が失敗することも考えられます。
これらの課題を解決するためのソリューションとして Cloud Composer が挙げられます。 Cloud Composer を活用することで、データパイプラインの依存関係や処理状況ステータスを一元的に管理し、下流処理の一括リトライが可能になります。
下図右側の画像は、一つのパイプラインに複数の処理が連なっている様子を表したものです。
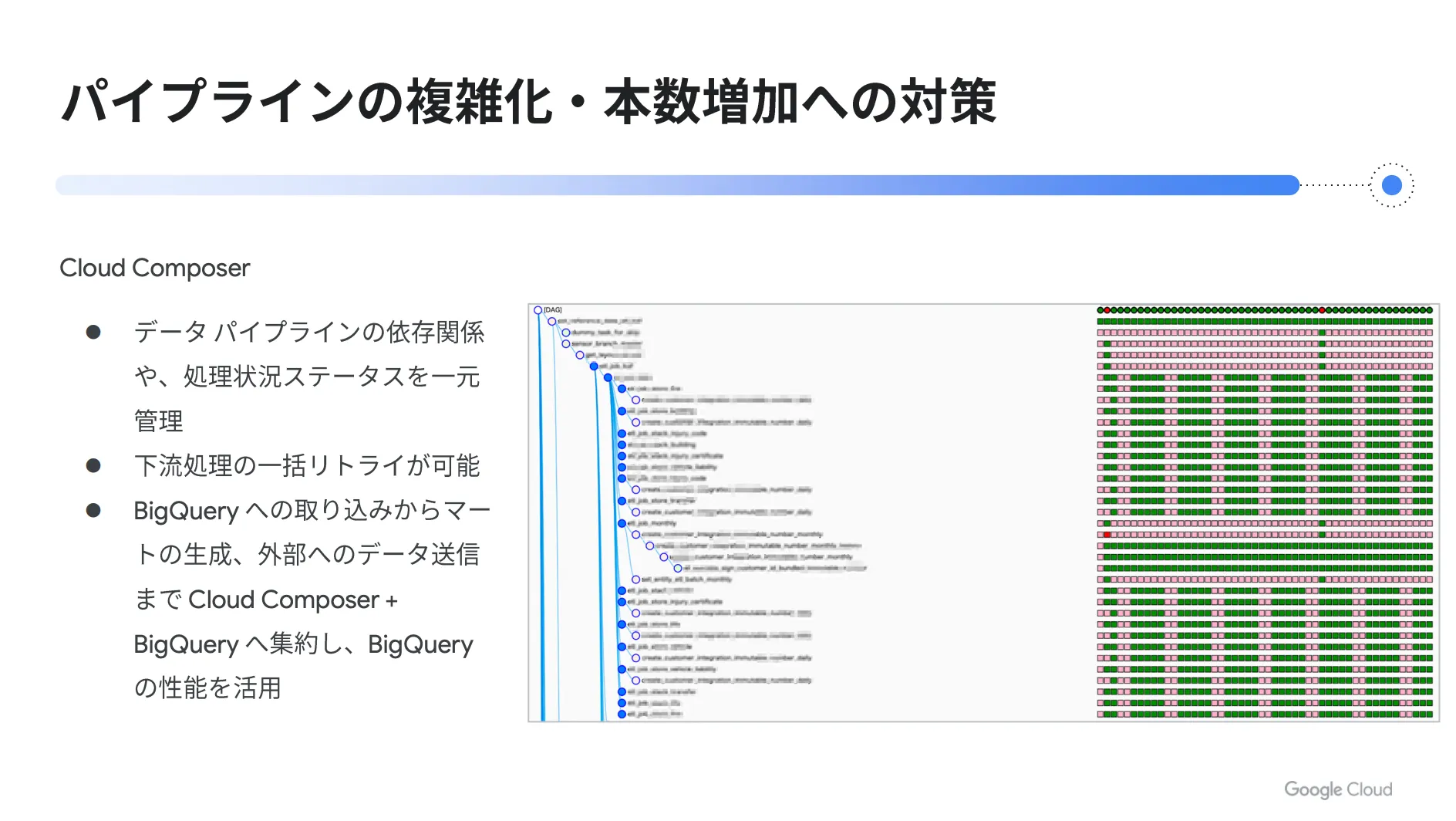
縦に並んでいる処理が各タスクであり、前の処理が終わると後続の処理が複数同時に起動する制御や、待ち合わせのような制御など、状況に応じて柔軟に設定することができます。
また、一番右側の色が付いている部分は、各処理の実行ステータスを視覚的に表したものであり、「緑 = 成功した処理」、「赤 = 失敗した処理」、「ピンク = スキップした処理」を意味しています。例えば、このパイプラインを日次で実行している場合、色が付いている部分の最右列が直近の実行結果を表示する箇所となり、その左の列が前日分の実行結果を表示する箇所になります。
このように、 Cloud Composer を使えば、複数ステップの処理や実行単位ごとの実行結果を一元的に確認できます。そのため、複数の処理が走っている場合でも、失敗した箇所を視覚的に把握することが可能になりますし、失敗した処理やその下流の処理を一括でリトライする機能も備わっているため、効率的にパイプラインを運用することができます。
前章のステップ2までは、多くのサービスや機能を組み合わせてパイプラインを構築する部分についてご説明しましたが、これらの呼び出しを Cloud Composer に集約すれば、全体の状況をわかりやすく一元管理できます。パイプラインを運用する上で、この点は大きなメリットであると言えるでしょう。
Cloud Composerに関して理解を深めたい方は以下の記事もあわせてご覧ください。
Google のワークフロー構築サービス「 Cloud Composer 」とは?概要、特徴、料金体系、できることまで徹底解説!
BigQuery に関する Q&A
Q.オンプレミスの社内ネットワークから BigQuery へデータを移行する場合、利用するネットワークは「インターネット」「VPN」「専用線」のどれが一般的でしょうか?
A.データ量が多い場合や、よりセキュアな通信を求める場合は Cloud Interconnect がオススメです。なお、小規模な場合には、インターネット経由で HTTPS による通信ならすぐに始められます。
Q.先ほどお話があった Step 2のような場面で、一度ファイルを加工してから BigQuery へ取り込む場合はどのような構成が良いでしょうか?
A. Cloud Storage から直接 BigQuery へロードせずに加工をはさみたい場合は、 Cloud Functions で一度読み込んで加工してから BigQuery へ取り込む方法があります。仮に Cloud Functions のタイムアウト時間を超えるか、メモリに乗り切らない場合は、 Cloud Run や Dataflow の利用を検討してください。
まとめ
本記事では、 BigQuery を活用したデータ分析基盤の構築方法を具体的な3ステップに分けてご説明しました。内容をご理解いただけましたでしょうか?
以下、記事内容のまとめになります。

まずは BigQuery の基本的な機能と使い方を把握し、実際に触ってみてください。次に、 Google Cloud (GCP)の各サービスとの連携について理解を深めましょう。 BigQuery は単体でも優秀なサービスですが、 Google Cloud (GCP)の各サービスと連携することで、さらに利便性が向上します。そして、最後にパイプラインが複雑化・本数増加した時に備えて、運用視点でパイプライン全体を一元的に管理できる仕組みを検討してください。
そして、 Google Cloud (GCP)を契約するのであれば、トップゲートがオススメです。弊社トップゲートでは、 Google Cloud (GCP)のすべてをワンストップで提供しています。

また、 Google Workspace や Chromebook の取り扱いも行っており、コンサルティングやシステムの受託・開発にも対応しています。さらに、 Google 公式のアワードを3年連続で受賞しているため、安心して Google Cloud (GCP)の導入を任せることができます。
加えて、トップゲートでは T-PAS ( TOPGATE Professional Advisory Service )というサービスを提供しており、 Google Cloud (GCP)を熟知したエンジニアがお客様の Google Cloud (GCP)活用を全面的にサポートします。例えば、今回の記事で取り上げているデータ分析基盤の構築をお手伝いすることも可能です。

なお、トップゲートは Google Cloud (GCP)の支払代行サービスを行っており、トップゲートで Google Cloud (GCP)を契約することで、以下のような様々なメリットを享受できます。

本記事を参考にして、ぜひ Google Cloud (GCP)の導入を検討してみてはいかがでしょうか?
弊社トップゲートでは、専門的な知見を活かし、
- Google Cloud (GCP)支払い代行
- システム構築からアプリケーション開発
- Google Cloud (GCP)運用サポート
- Google Cloud (GCP)に関する技術サポート、コンサルティング
など幅広くあなたのビジネスを加速させるためにサポートをワンストップで対応することが可能です。
Google Workspace(旧G Suite)に関しても、実績に裏付けられた技術力やさまざまな導入支援実績があります。あなたの状況に最適な利用方法の提案から運用のサポートまでのあなたに寄り添ったサポートを実現します!
Google Cloud (GCP)、またはGoogle Workspace(旧G Suite)の導入をご検討をされている方はお気軽にお問い合わせください。