Google Speech To Text API とは?メリットや機能、ユースケース、料金体系まで徹底解説!
- AI
- API
- Cloud
- 音声認識
Google Speech To Text API をご存知でしょうか? Google が提供する API の一つであり、高性能な機械学習モデルによって、音声データをテキストデータへ変換できます。
本記事では、 Google Speech To Text API とは何か?という基礎的な内容から、 Google Speech To Text API のメリットや機能、ユースケース、料金体系など、あらゆる観点から一挙にご紹介します。
Google Speech To Text API とは?
Google Cloud Speech To Text API は、機械学習を活用して音声をテキストに変換してくれる Google の API サービスです。音声認識の精度が高く、多くの言語にも対応しているということで、高い評判を得ている API です。
API とは「 Application Programming Interface 」の頭文字を取った言葉であり、「アプリケーションをプログラミングするためのインターフェース」を意味しています。なお、インターフェースとは、異なる機器・装置を接続し、交信や制御を行うための装置やソフトウェアのことです。つまり API とは、アプリケーションとプログラムを繋ぐための役割を持つものであるとご理解ください。
Google Cloud Speech To Text API を活用することで、動画から字幕を自動算出することができます。そのため、 YouTuber のような動画制作者は、テロップ作成の工数削減を実現することができます。また、議事録作成の自動化も可能であり、ビジネスシーンにおいて、幅広い活躍が期待されるサービスです。
さらに、音声に含まれる数字を自動的に住所・年・通貨などに変換することも可能です。加えて、例えば電話による通話に特化した、予め用意されている音声認識モデルを利用する「ドメイン固有モデル」という機能が搭載されています。
Google Speech To Text API のメリット
Google Speech To Text API には、どのようなメリットがあるのでしょうか?代表的なものをいくつかご紹介します。
精度が高い
Google Speech To Text API は、 Google における最新のディープラーニングのニューラルネットワークアルゴリズムを採用しており、これによって自動音声認識(ASR)を実現しています。そのため、とても高い精度で音声データをテキスト化することができます。
モデルを簡単にカスタマイズできる
Google Speech To Text API のユーザーインターフェースでは、カスタムリソースのテスト、作成、管理を簡単に行うことができます。このように、モデルを手間なくカスタマイズできる点は Google Speech To Text API の大きなメリットだと言えるでしょう。
柔軟にデプロイできる
Google Speech To Text API は、環境に合わせて柔軟に音声認識をデプロイできます。例えば、クラウド環境の場合は API を使えますし、オンプレミス環境であれば Google Speech to Text On-Prem を使用することで、デプロイが可能になります。
Google Speech To Text API の機能
Google Speech To Text API には様々な機能が搭載されています。順番に内容を見ていきましょう。
グローバルな語彙対応
Google Speech To Text API は、125以上の言語や言語変種におよぶ広範な言語に対応しており、世界中のユーザーベースをサポートしています。
ストリーミング音声認識
アプリケーションのマイクからストリーミングした音声入力や、事前に録音した音声ファイル(インラインや Cloud Storage )から取得した音声入力を API が処理するのに伴って、音声認識の結果をリアルタイムに受け取ることができます。
音声適応
ヒントを提供することで、分野特有の用語やあまり使われない単語を音声文字変換するように音声認識をカスタマイズし、特定の単語やフレーズの音声文字変換の精度を向上できます。また、クラスを使用して音声の数字を住所、年、通貨などに自動的に変換することも可能です。
品質を容易に比較
Google Speech To Text API では、使いやすいユーザーインターフェースを使用して音声をテストできます。これにより、様々な構成を試して、品質と精度を最適化することが可能になります。
Speech to Text On-Prem
Google の音声認識技術を独自のプライベートデータセンターにてオンプレミスで活用することで、オンプレミス環境においても音声認識をデプロイすることが可能になります。
ノイズ耐性
Google Speech To Text API は、雑音の多い音声も正常に処理できます。別途ノイズキャンセルを行う必要はなく、手間なく運用できる点も大きな魅力となっています。
コンテンツフィルタリング
フィルタを活用することで、音声データ内の不適切なコンテンツや職業倫理に反するコンテンツを検出し、テキスト結果の冒とく的な語句をフィルタで除外するのに役立ちます。
Google Speech To Text API のユースケース
Google Speech To Text API は、どのような場面で活用できるのでしょうか?具体的なユースケースをいくつかご紹介します。
なお、ここで掲載している画像は Google Cloud 公式ページを参照しています。
カスタマーサービスの改善
IVR (インタラクティブ音声レスポンス)とエージェントの会話をコールセンターに追加することにより、カスタマーサービスシステムを強化できます。さらに、会話データを分析し、通話と顧客についてより多くの分析情報を得ることで、今後の運用に反映することが可能です。
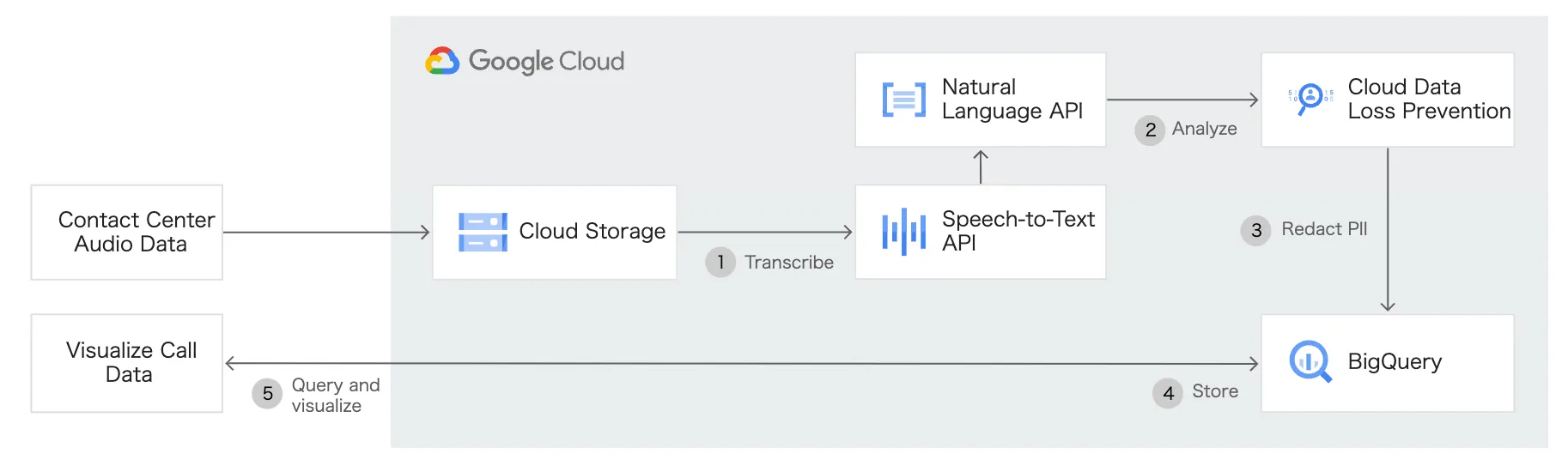
コールセンターなどのコンタクトセンターのDXについて興味関心がある方は以下の記事もオススメです。
コンタクトセンター DX を実現! Contact Center AI を活用した実践的な業務デジタル化のアプローチとは?
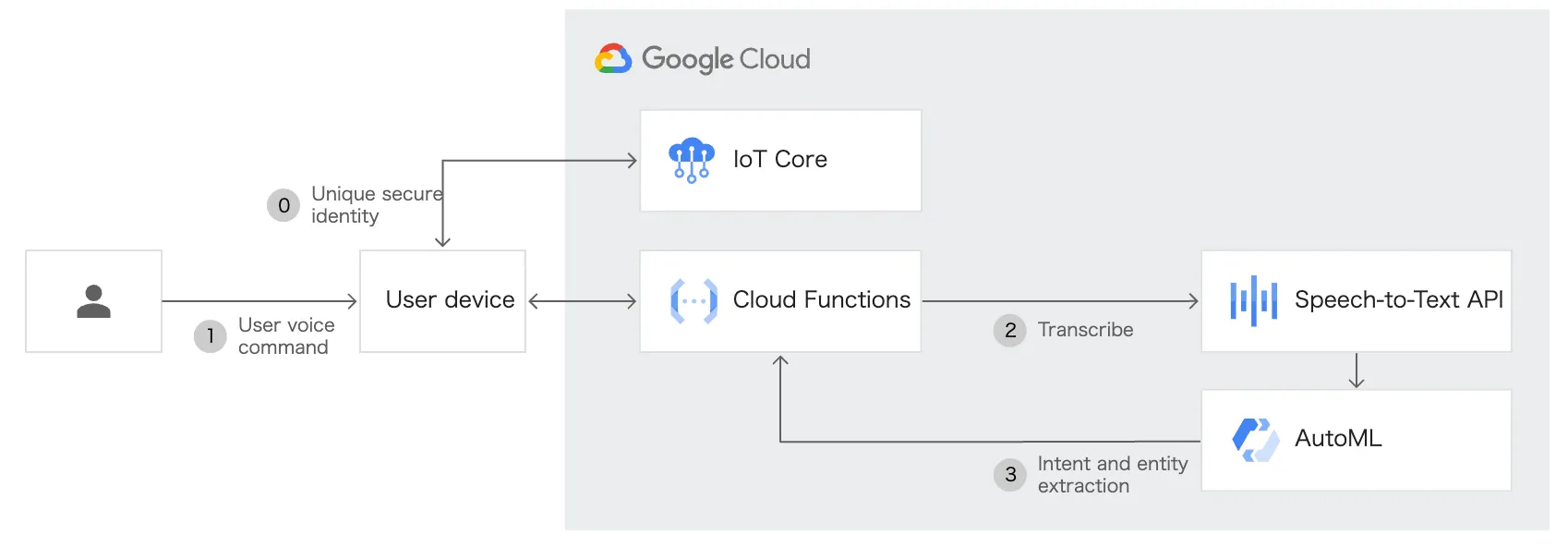
音声操作の有効化
例えば、「音量を上げて」などの音声コマンドや「パリの気温は?」などの音声検索を実装できます。これに Google Speech To Text API を組み合わせることで、 IoT アプリケーションで音声対応のエクスペリエンスを提供します。
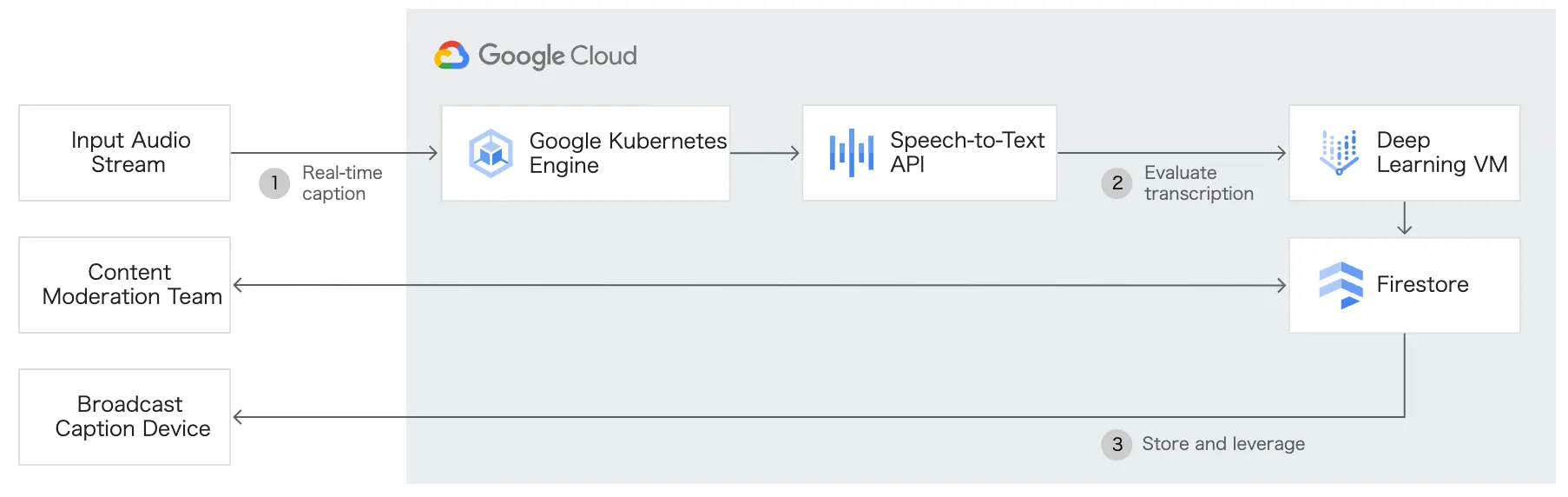
マルチメディアコンテンツの音声文字変換
Google Speech To Text API は音声や動画の音声文字変換を行い、リアルタイムで字幕をストリーミングコンテンツに追加することができます。動画の音声文字変換モデルは、動画や複数話者のコンテンツのインデックス作成または字幕作成に適しており、 YouTube の動画字幕作成機能に似た機械学習技術を使用しています。
Google Speech To Text API の料金体系
ここからは、 Google Speech To Text API の料金体系についてご説明します。
Google Speech To Text API では、正常に処理された音声の長さに基づいて月ごとに請求され、15秒単位で切り上げて計算されます。なお、エラーとなったリクエストはカウントされないため、この場合は料金が発生しません。
料金表
以下、 Google Speech To Text API の料金を表にまとめます。
大きく分けて、「標準モデル(動画・通話以外)」と「拡張モデル(動画・通話)」の2つに分類されます。
| 機能 | 標準モデル(0〜60分) | 標準モデル(60分超〜100万分) | 拡張モデル(0〜60分) | 拡張モデル(60分超〜100万分) |
|---|---|---|---|---|
| 音声認識(データロギングなし) | 無料 | 0.006米ドル(15秒あたり) | 無料 | 0.009米ドル(15秒あたり) |
| 音声認識(データロギングあり) | 無料 | 0.004米ドル(15秒あたり) | 無料 | 0.006米ドル(15秒あたり) |
このように、 Google Speech To Text API では、0〜60分までは無料で使えますが、60分を超えると機能ごとに設定された料金が15秒あたりで発生します。
料金の決定要素
Google Speech To Text API の料金は、次の3つの要素を基にして決定されます。
- 認識に標準または拡張モデルを使用したか
- データロギングを有効にしたか
- 認識対象の音声のチャンネル数
以下、それぞれについて詳しくご説明します。
拡張モデル
Google Speech To Text API には、音声認識に使用できる複数の機械学習モデルがあります。このうち、拡張音声通話モデルと拡張動画モデルは高度な認識性能を備えており、適切に使用することで高品質な結果が得られます。
データロギング
データロギングを有効にすると、 Google Speech To Text API に送信された音声データを Google が記録するのを許可したことになります。このデータは、 Google が音声文字変換に使用する機械学習モデルの改善のために利用されます。そのため、データロギングを有効にした場合の Google Speech To Text API の料金は割安に設定されています。
マルチチャンネル
Google Speech To Text API では、音声チャンネルごとに課金されます。マルチチャンネルのリクエストを送信すると、すべてのチャンネルで処理された音声の合計の長さに基づいて課金されます。
この時間の処理は、月間の使用量上限のトラッキング方法とは異なり、音声ファイルの長さによってのみ決定されます。例えば、4チャンネルある30秒間の音声をリクエストした場合は120秒分の課金が発生しますが、月間の割り当てに対しては30秒間のみがカウントされます。
料金の計算方法
Google Speech To Text API における各リクエストは、15秒単位で切り上げられます。また、15秒単位で切り上げられる際は、小数点以下の秒数も対象になるため、例えば「15.14秒」は「30秒」として請求されます。
なお、月あたりの利用は「100万分まで」と決められています。仮に音声の使用が「100万分/月」を超える場合には、プロジェクトの Google Speech To Text API 割り当てリクエストを送信する必要があります。
加えて、認識する音声ファイルを Google Cloud Storage に保存する場合や、他の Google Cloud (GCP)のリソースを Google Speech To Text API と併用する場合は、そのサービスの利用料も請求の対象となるため、この点には注意が必要です。
その他の費用を試算するには、 Google Cloud (GCP)の料金計算ツールが役立ちます。
音声のテキスト変換は Google Cloud (GCP)がオススメ
ここまで、 Google Speech To Text API について詳しくご説明しましたが、市場には Google Speech To Text API 以外にも音声データをテキストに変換できるサービスが多数存在します。例えば、 IBM 社が提供している IBM Cloud の Text to Speech Watson などが挙げられます。
しかし、せっかく音声のテキスト化サービスを導入するのであれば Google Cloud (GCP)がオススメです。
AWS 、 Google Cloud (GCP) 、 Azure 、 Watson 、の音声認識AIについて比較した記事があるので、ご興味ある方は以下の記事もご覧ください。
パブリッククラウドAWS GCP Azure Watsonの音声認識AIを価格や機能、精度の観点で比較!
Google Speech To Text API は Google Cloud (GCP)に内包されているサービスの一つであるため、 Google Speech To Text API を利用するためには Google Cloud (GCP)を契約する必要があります。
最後に、 Google Cloud (GCP)の概要とオススメな理由をご説明します。
Google Cloud (GCP)とは?
Google Cloud (GCP) は Google が提供するパブリッククラウドサービスです。同じ種別のサービスとしては、 Microsoft 提供の「 Azure 」や Amazon 提供の「 AWS 」などが挙げられます。
Google Cloud (GCP) は、セキュアで高い安定性を持つ Google の IT プラットフォーム環境を自社で利用することができます。ビッグデータや Google Workspace との連携など、『クラウド利用を越えた先の IT 戦略』をシームレスに実現することが可能です。
また、「 BigQuery 」をはじめとした優れたデータ解析ツールが用意されているため、一部のエキスパートだけでなく、組織全体でデータを活用し、経営戦略の策定や業務改善に繋げていくことが可能です。さらに Google Cloud(GCP) の多種多様なサービスを活用することで、高精度なデータ分析を実現することができます。
ユーザーインターフェースが使いやすい
Google Cloud (GCP)の大きな特徴として、使いやすいユーザーインタフェースが挙げられます。あらゆる操作がボタンクリックやドラッグ&ドロップなどで完結するため、専門知識を持たない人でも簡単に使うことができます。これにより、組織全体で社内のデータを有効活用でき、画像認識に関してもスムーズに作業を進めることが可能です。
豊富なソリューションが揃っている
Google Cloud (GCP)には、多彩な機能がオールインワンで提供されています。今回ご紹介した Google Speech To Text API はもちろんのこと、その他にも多種多様なサービスが備わっています。
例えば、
- Cloud Vision API (画像データを認識して情報を取得)
- Cloud Translation API (任意の文字列をサポートされている言語に翻訳)
などが挙げられます。これらを Google Speech To Text API と組み合わせて使うことで、様々なシーンにおける業務効率化や生産性向上を実現できます。
データ処理速度が速い
音声データをテキスト化する際、データの処理速度は重要なポイントの一つになります。膨大なデータを効率的に処理するには、高いサービススペックが求められるためです。
Google Cloud (GCP) は月間60億時間分の動画を再生する YouTube や、10億人のユーザーが利用している Gmail と同じインフラをベースとしています。そのため、高速で安定したパフォーマンスを誇り、大量のデータに対してもスムーズなリアルタイム処理を実現します。
柔軟にスケーリングできる
Google Cloud (GCP)は 100% クラウドで提供されているサービスであるため、状況に合わせて柔軟にスケーリングできます。将来的にデータ量が増加した場合でも簡単にリソースを追加できるため、安心してサービスを運用することができます。
また、 Google Cloud (GCP) は自動スケーリングに対応しており、自社の状況に応じてリソースを自動的に増減してくれます。そのため、管理者が都度設定を変更したり、煩雑なリソース調整を行う必要はありません。面倒な作業は Google Cloud (GCP) が自動で行ってくれるため、自社は本来注力すべき作業に集中することができ、結果的に業務効率化や生産性向上に直結します。
セキュリティレベルが高い
Google Cloud (GCP) は第三者認証取得のハイレベルなセキュリティを備えており、
- SSAE16 / ISAE 3402 Type II:SOC 2/SOC 3
- ISO 27001・FISMA Moderate
- PCI DSS v3.0
など、さまざまな年次監査を受けています。
そのため、安全なセキュリティ環境で画像認識を行うことができ、情報漏洩などの各種リスクを低減した形で、安心して作業を進めることが可能になります。
まとめ
本記事では、 Google Speech To Text API とは何か?という基礎的な内容から、 Google Speech To Text API のメリットや機能、ユースケース、料金体系など、あらゆる観点から一挙にご紹介しました。
機械学習や AI が広く普及した現代において、音声データのテキスト化は益々重要になっています。 Google Speech To Text API は、企業成長を加速するための有効な武器になると言えるでしょう。
Google Speech To Text API を活用することで、音声データを高い精度でテキスト化することができ、モデルのカスタマイズも簡単に行えます。また、柔軟にデプロイできる点も大きな魅力の一つです。
音声データをテキスト化できるサービスは多く存在しますが、せっかく導入するのであれば Google Cloud (GCP)がオススメです。使いやすいユーザーインターフェースや高速データ処理、高いセキュリティレベルなど、企業は様々なメリットを享受できます。
本記事を参考にして、 Google Cloud (GCP)の導入および、 Google Speech To Text API の活用を検討してみてはいかがでしょうか?
弊社トップゲートでは、Google Cloud (GCP) 利用料3%OFFや支払代行手数料無料、請求書払い可能などGoogle Cloud (GCP)をお得に便利に利用できます。さらに専門的な知見を活かし、幅広くあなたのビジネスを加速させるためにサポートをワンストップで対応することが可能です。
Google Workspace(旧G Suite)に関しても、実績に裏付けられた技術力やさまざまな導入支援実績があります。あなたの状況に最適な利用方法の提案から運用のサポートまでのあなたに寄り添ったサポートを実現します!
Google Cloud (GCP)、またはGoogle Workspace(旧G Suite)の導入をご検討をされている方はお気軽にお問い合わせください。
メール登録者数3万人!TOPGATE MAGAZINE大好評配信中!
Google Cloud(GCP)、Google Workspace(旧G Suite) 、TOPGATEの最新情報が満載!