【 Google Cloud 入門編・第10回】スケーラブルな NoSQL データベースサービス Cloud Bigtable を使ってみよう!
- Cloud
- GCP入門編
- Golang
この記事では、 Google Cloud のストレージサービスのひとつである、 Cloud Bigtable について紹介します。 Bigtable といえば、 NoSQL という概念が登場した初期から話題になることの多かった Google の内製ストレージシステムです。 Bigtable は Google 社内でのみ使用されるシステムでしたが、2006年に論文が公開されたことで存在が公になりました。現在多くのサービスが使用している HBase が、 Bigtable の論文をもとにして開発されたことは有名です。
GCP では、2015年から Bigtable をサービスの一部として利用することができるようになっています。 Bigtable の使いどころや特徴の解説、 Bigtable を利用する簡単なデモを通して、その強力な機能について知っていただければと思います。
この記事の目的
- Cloud Bigtable の使いどころや特徴を学ぼう。
- Cloud Bigtable の簡単なデモを通して、使い方を覚えよう。
Cloud Bigtable とは
Bigtable は、2006年に Google が公開した論文で、その詳細が明かされた Google の内製ストレージシステムです。特徴は、サーバー数を増やすことでペタバイト級の巨大なデータを扱えるスケーラブルな設計、要求される性能が高スループットであろうと低レイテンシーであろうと対応することができるパフォーマンスの高さ、そしてリレーションをサポートしない列指向のデータベースであるといったところでしょう。
Google では検索システムのインデックスの保存や、 Google Analytics のユーザーの行動データの蓄積、 Google Map や Google Earth のデータストアとしてなど、様々な用途に利用されています。 Bigtable は分散ロックサービスの Chubby 、分散ファイルシステムの Google File System (GFS)に依存しており、 GFS を中心としたこのエコシステムはそのまま Hadoop とそのサブプロジェクトに大きな影響を与えました。 この中でも HBase は、 Bigtable の論文を基に実装されたシステムです。
Cloud Bigtable はどのような場面に適しているか?
高いスループットをもち、データサイズが巨大になっても動作するというスケーラビリティを持つ一方、 RDBMS でおなじみの関連モデルを扱えないなど、かなり癖の強そうな Bigtable ですが、どのような場面に適しているのでしょうか。 Cloud Bigtable のドキュメントには、 最適なユースケースとして、金融取引のデータ、株価の変動データ、 IoT デバイスから出力されるデータ、時系列データが挙げられています。また、高いスループットが求められること、1つ1つの値は10メガバイトを超えないこと、といったことも注意点として書かれています。さらに、1テラバイトにデータが収まる場合には向かない、といったことも書かれています。ドキュメント中の ”Cloud Bigtable and other storage options” には、この場合はこの製品が適している、といった選択肢が挙げられていますので、 Cloud Bigtable を検討する際には参照するとよいでしょう。
Cloud Bigtable を使ってみよう
さて、それでは実際に Bigtable を使用してみましょう。 MySQL や PostgreSQL のような RDBMS に慣れていると、新鮮な感覚がするのではと思います。
Cloud Bigtable のインスタンスを立ち上げる
まずは GCP のコンソールを開き、左上メニューをクリックし、 ”API Manager” のページを開きます。 API Manager で ”Library” をクリックし、検索ボックスに ”Cloud Bigtable” と入力します。
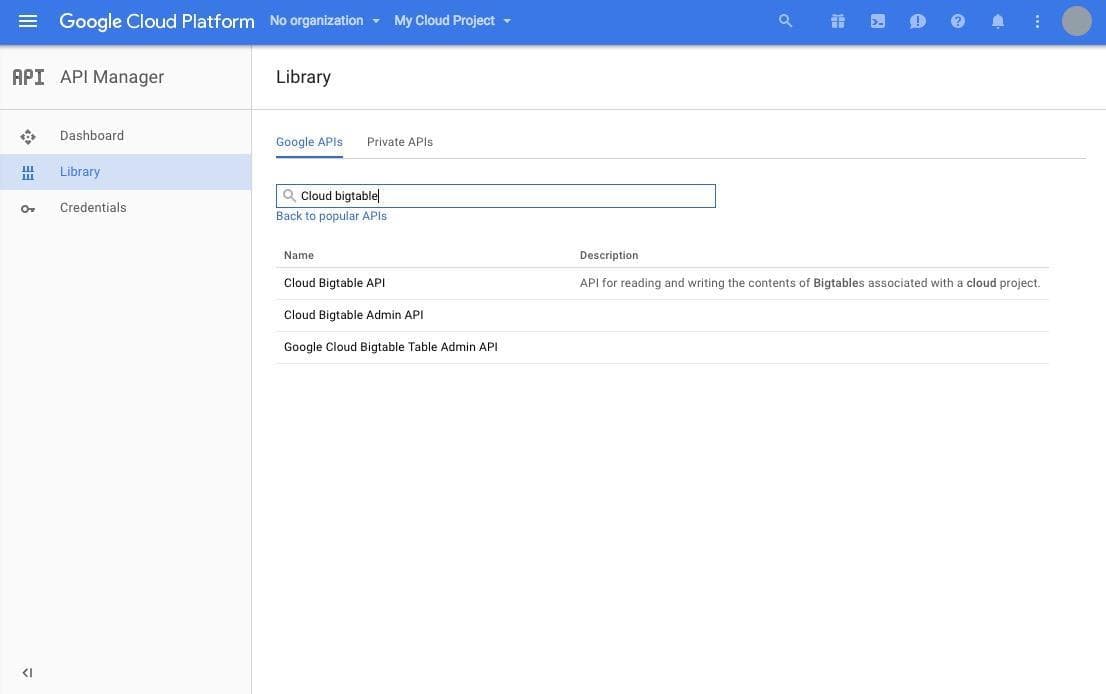
ここで表示される API のうち、 ”Cloud Bigtable API” と ”Cloud Bigtable Admin API” をそれぞれ有効にしましょう。APIの名前をクリックしてジャンプした先にある [ENABLE] を押すと、 API が有効化されます。
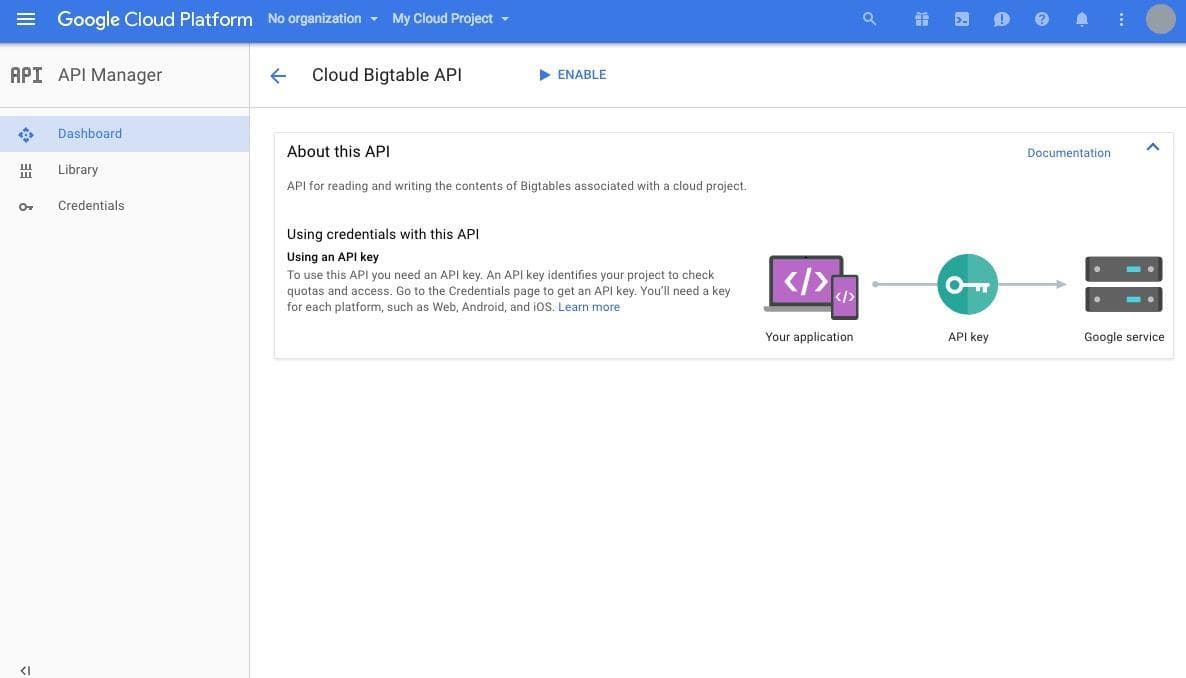
API の有効化が完了したら、次は Cloud Bigtable のインスタンスを起動しましょう。インスタンスの起動はコンソール左上のメニューボタンを押して表示したメニューの "Bigtable" をクリックした先で行います。
初期状態では画面中央にサービスの紹介と、 [Create Instance] と [Learn More] のボタン以外は何も表示されていないかと思います。 [Create Instance] をクリックしましょう。
“Instance name” の欄に bigtable-instance-1 と入力します。入力が完了すると、 Instance ID 、 Cluster ID が自動的に生成されます。記事執筆時点では、選択できる Zone に asia-northeast1-a はありませんので、ここでは "asia-east1-a" を選択します。ノード数はデフォルトの3、 Storage Type は SSD にしておきます。なお、 SSD と HDD を選択するとパフォーマンスとコストの表示が切り替わります。実際に利用する際には、コストとワークロードに合わせて選択してください。
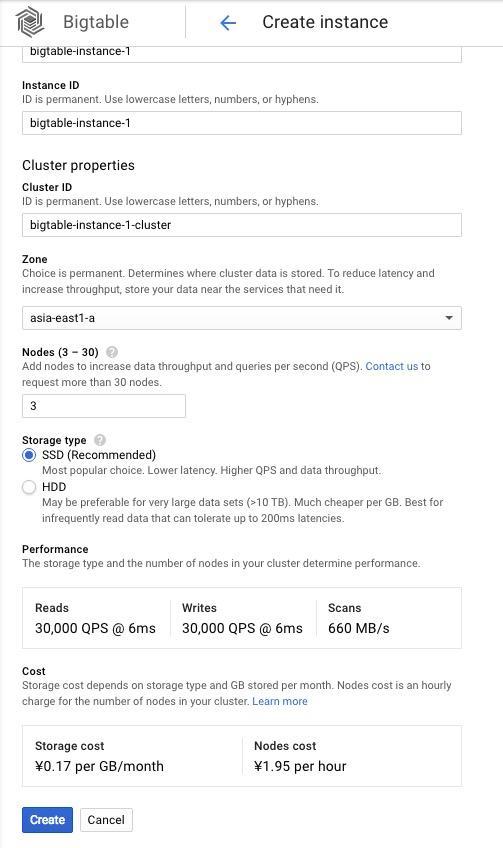
[Create] を押すと、インスタンスの起動が開始されます。起動が完了すると、以下の画面のようになっているでしょう。
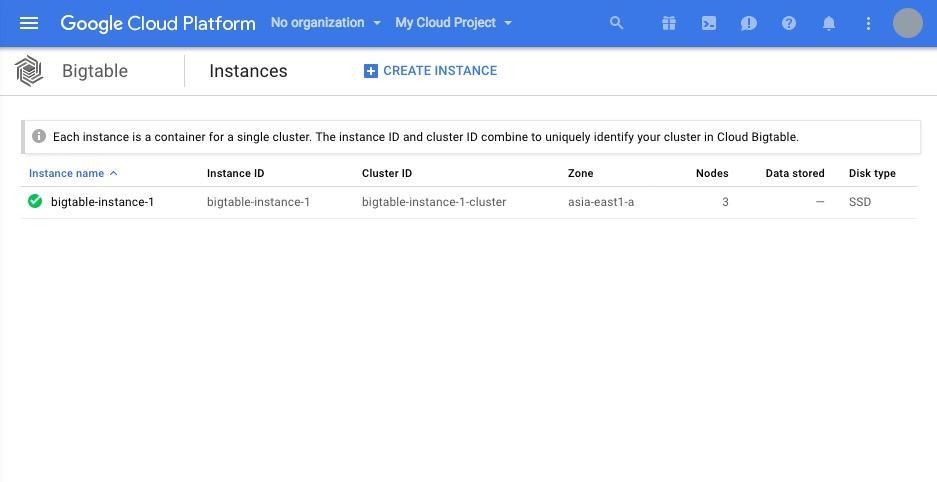
cbt を使って Cloud Bigtable に接続する
次に、コマンドラインツールである cbt を利用して、 Cloud Bigtable に接続してみます。 cbt を利用するには、 Go 言語のランタイムが必要です。このページを参考にして、ランタイムをインストールしてください。その際、 $GOPATH/bin をパスに追加することを忘れないでください。 bash であれば、 ~/.bashrc もしくは ~/.bash_profile に以下のように追記します。
export PATH="$PATH:$GOPATH/bin"
さて、 Go 言語のランタイムのインストールが完了したら、 cbt のインストールを行います。以下のコマンドで cbt をインストールすることができます。
$ go get -u cloud.google.com/go/bigtable/cmd/cbt

特に何も出力されませんが、これで正常にインストールは完了しています。以下のコマンドで確認してみましょう。
$ cbt
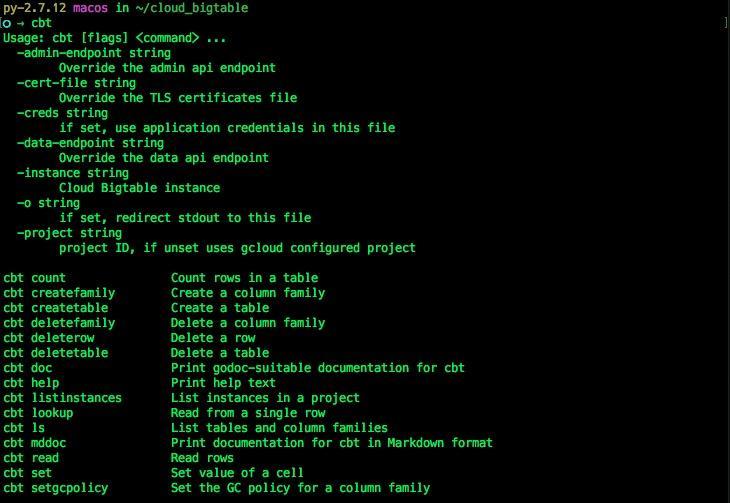
ヘルプが表示され、インストールが成功したことがわかります。次に、以下の設定ファイルを ”~/.cbtrc” に記述します。
project = プロジェクト名
instance = bigtable-instance-1
これで cbt の設定は完了です。 Cloud Bigtable を操作してみましょう。
cbt で Cloud Bigtable を操作する
まず、テーブルを作成します。テーブルは、 RDBMS でいうところのテーブルと似たような概念です。
$ cbt createtable test-table

gcloud コマンドの認証情報が利用された事以外は特に何も出力がありません。以下のコマンドでテーブルの作成を確認します。
$ cbt ls

test-table という名前のテーブルが作成されています。次に、テーブルに対してカラムファミリーを追加します。カラムファミリーは Bigtable のアクセスコントロールの最小単位で、複数のカラムをまとめたものです。 Bigtable ではテーブルに対してまずカラムファミリーを作成し、そのカラムファミリーにカラム(キー)と値を入力する、という順番で操作を行います。
まず、 test-table に対して新しいカラムファミリー、 testcf を追加します。
$ cbt createfamily test-table testcf

カラムファミリーの追加を確認します。
$ cbt ls test-table

それでは、値を格納してみましょう。
$ cbt set test-table r1 testcf:column1=test-value
$ cbt set test-table r2 testcf:column1=test-value2
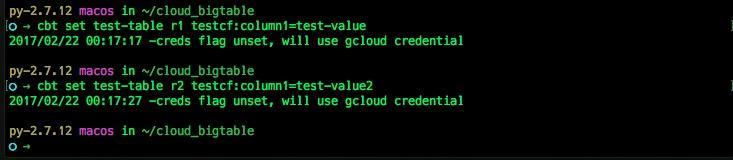
次に、テーブルに格納された値を読み出します。
$ cbt read test-table
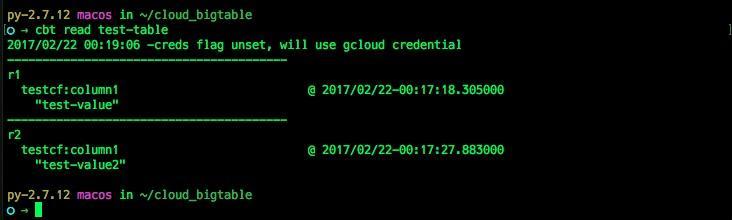
値が格納されていることがわかります。
cbt では、データの読み出しを行う read コマンドに指定できるのは、 row の prefix と start 、 end 取得するデータの数である count くらいで、複雑なクエリを投げることはできません。集計処理といった複雑なデータ処理を行う際は、 API を使うか、 Cloud Dataproc を利用することになります。
最後に、テーブルを削除し、インスタンスを削除します。
$ cbt deletetable test-table

インスタンスの削除は、 GCP のコンソールから、 Cloud Bigtable のインスタンス画面を表示し、画面右上にある [DELETE] をクリックします。
おわりに
Bigtable のインスタンスを起動し、テーブルを作成して値を追加しました。 RDBMS のように複雑なクエリを使うことができないことから、大量のデータを高速に追加し続ける用途に最適化されたシステム、といった印象を受けるかもしれません。
Bigtable は1つのことに特化したシステムであり、単体で利用するというよりも他のツールと組み合わせて使用することで力を発揮するタイプのシステムだと感じます。 GCP 及び外部のツールとの統合に関しては、ドキュメントに詳しい解説があります。是非こちらも参照してみてください。
弊社トップゲートでは、Google Cloud (GCP) 利用料3%OFFや支払代行手数料無料、請求書払い可能などGoogle Cloud (GCP)をお得に便利に利用できます。さらに専門的な知見を活かし、
- Google Cloud (GCP)支払い代行
- システム構築からアプリケーション開発
- Google Cloud (GCP)運用サポート
- Google Cloud (GCP)に関する技術サポート、コンサルティング
など幅広くあなたのビジネスを加速させるためにサポートをワンストップで対応することが可能です。
Google Workspace(旧G Suite)に関しても、実績に裏付けられた技術力やさまざまな導入支援実績があります。あなたの状況に最適な利用方法の提案から運用のサポートまでのあなたに寄り添ったサポートを実現します!
Google Cloud (GCP)、またはGoogle Workspace(旧G Suite)の導入をご検討をされている方はお気軽にお問い合わせください。
メール登録者数3万件!TOPGATE MAGAZINE大好評配信中!
Google Cloud(GCP)、Google Workspace(旧G Suite) 、TOPGATEの最新情報が満載!