【GCP入門編・第12回】 BigQuery を使って気軽にビッグデータの解析を行ってみよう!
- BigQuery
- GCP入門編
- ビッグデータ
Google Cloud (GCP) では、 Cloud Dataproc 、 Bigtable などのビッグデータを扱うためのサービスが数多く提供されています。これは、検索エンジンという膨大なウェブ上のデータと常に向き合ってきた Google に、ビッグデータを扱うためのノウハウが蓄積していることの現れです。 Google が開発した数々のビッグデータ向けの技術を使うことができる点は、 AWS や Azure などの競合サービスにはない、 GCP の大きな特徴です。
BigQuery は、 Web ブラウザからの操作だけで、気軽にテラバイト、ペタバイト級のデータを扱って解析が行えます。分かりやすく、非常に便利に使えるので、エンジニアでない方にも是非試していただきたいサービスです。
この記事では、ビッグデータを扱うサービスの1つである BigQuery について紹介し、データを BigQuery に取り込み、解析するデモを行います。
この記事の目的
- BigQuery とは何かを理解しよう。
- CSV 形式のデータを BigQuery に取り込み、解析を行ってみよう。
BigQuery とは
BigQuery は、Dremelという Google の社内データ解析ツールをサービスとして公開したものです。 Dremel はペタバイト級のデータを扱えるようにスケールを考えて設計されたソフトウェアです。非常にパワフルな一方、 エンジニアでなくとも SQL さえ覚えれば大量のデータを使って集計作業や解析作業を行うことが可能です。
こうした Dremel の利用しやすさから、 Google 社内ではクロールした Web のドキュメントの解析、スパム解析、日々ユーザーから送られてくる大量のアプリケーションのインストールデータの解析など、多種多様なタスクをこなすために使われています。
BigQuery はそんな Dremel を誰もが使えるようにしたサービスです。 BigQuery は、 Cloud Dataproc を使った Hadoop によるデータの解析と異なり、クラスターの展開も必要なければプログラミング言語を使ったジョブの記述も必要ありません。必要なのはデータを何らかの形で BigQuery にインポートすることだけです。この手軽さは、 GCP の他のサービスと比較してもトップレベルです。
BigQuery はデータのインポート元として、 Google Cloud Storage 、 File Upload 、 Google ドライブをサポートしています。つまり、 Google スプレッドシートのデータだろうと、手元に持っている CSV ファイルだろうとアップロードして解析できるのです。さらに、操作はすべて Web の UI から行えるため、コマンドラインを使う必要もありません。
それでは、実際に BigQuery にデータをインポートし、簡単な SQL 文を使ってデータの解析を行ってみます。
BigQuery を使ってみよう
このデモでは、サンプルデータとして国税庁が提供しているオープンデータを使用します。まずは、国税庁の法人番号公表サイトを開き、データをダウンロードします。比較的大きなデータを扱ってデモをするため、 Unicode の CSV 形式で提供されるデータから、東京都のデータを圧縮した zip ファイルをダウンロードします。
zip ファイルを解凍すると、180MB程度の CSV ファイル(記事執筆時点では13_tokyo_all_20170228.csv)が入ったフォルダが表示されます。まずはこちらを Google ドライブにアップロードしましょう。
前節 "BigQuery とは" では、 BigQuery はデータのインポート元として、 File Upload をサポートすると書きました。しかし、ウェブブラウザ経由のファイルアップロードには 10 MB という制限があります。このため、 このデモでは Google ドライブを使用します。
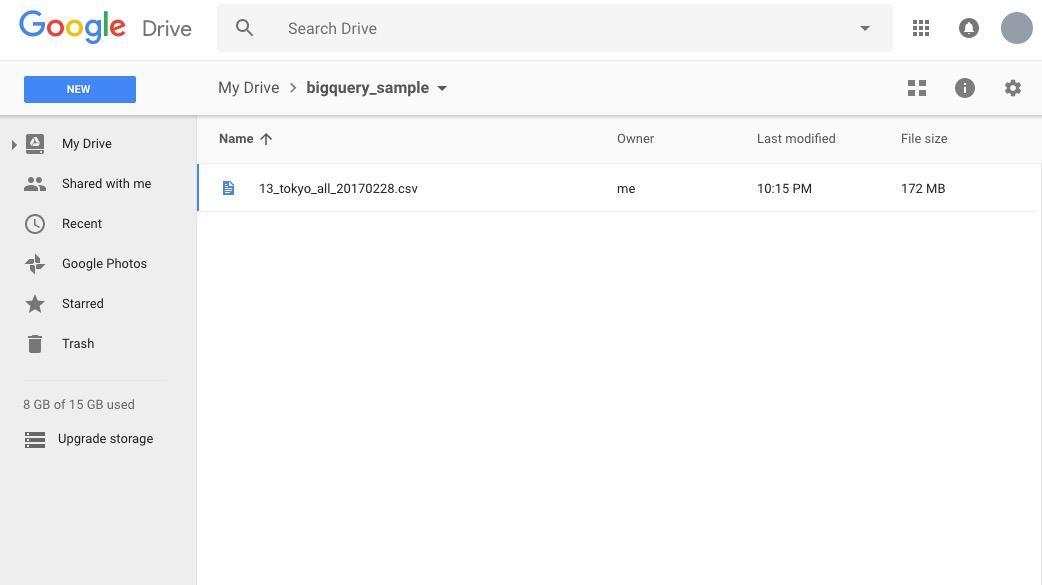
アップロードが完了したら、このファイルの URL を取得します。ファイルを右クリックし、 [Get Sharable Link] をクリックして URL を取得します。
ここまでが済んだら、 GCP のコンソールの左側メニューから [BigQuery] をクリックします。新しいウィンドウで BigQuery の Web インターフェースが開かれます。
左側のメニューには、プロジェクトが表示されています。プロジェクト名の右側にある下向きの三角をクリックし、 [Create new dataset] をクリックすると、以下のような画面が開きます。
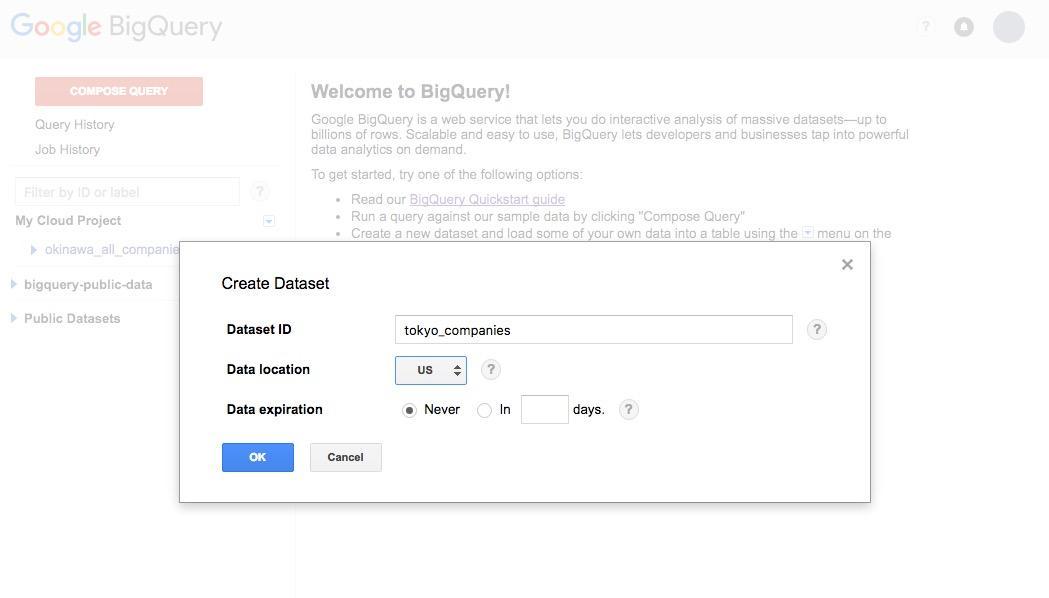
Dataset ID に ”tokyo_companies”、 Data location は US を選択します。この状態で [OK] をクリックすると、左側のメニューにデータセットが追加されます。次に、データセット名の右側に表示されている下向きの三角をクリックし、 [Create Table] をクリックします。表示された画面でデータのインポートを行います。
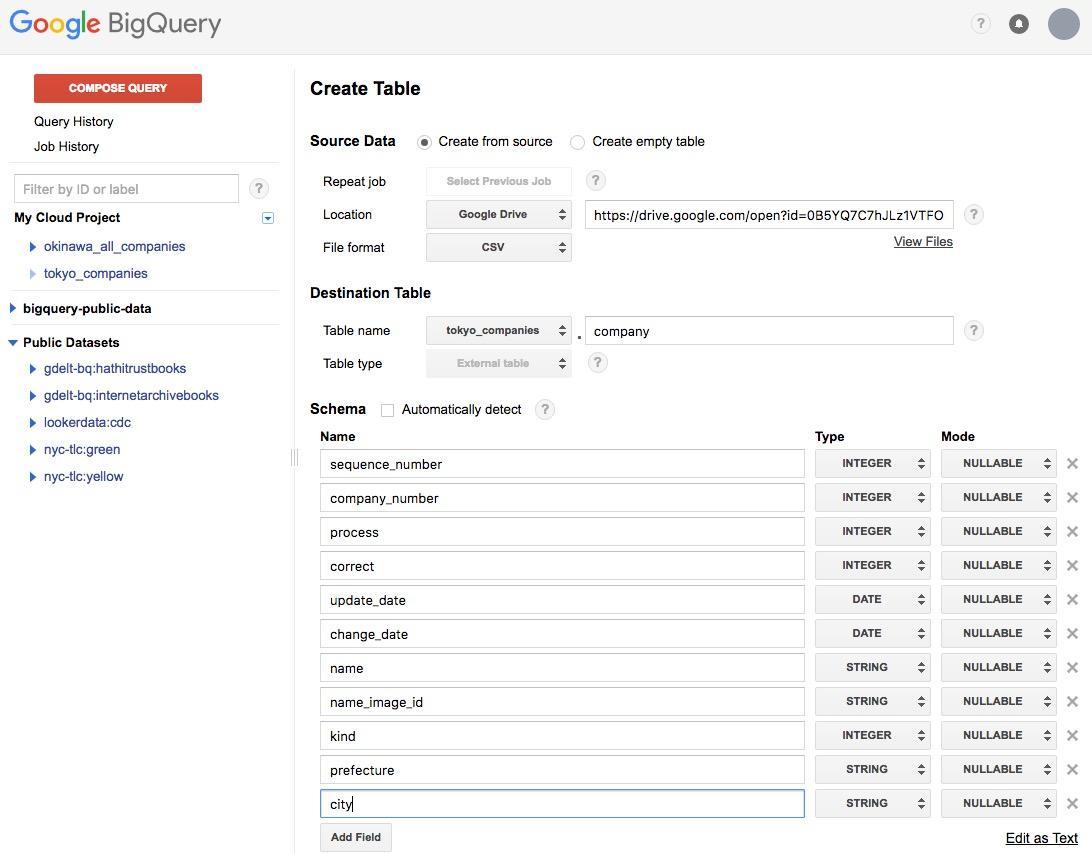
Location は Google Drive 、 URL に先ほどアップロードしたデータの URL を貼り付けます。 File Format は CSV を選択しましょう。 Table name には company と入力します。
Schema は、 RDBMS でいうところのスキーマと同じ概念です。上の画面を参考に入力してください。入力が完了したら、 [Create table] をクリックします。この時、 Google Drive にアクセスするために OAuth の許可画面が開きますので、アクセスを許可します。
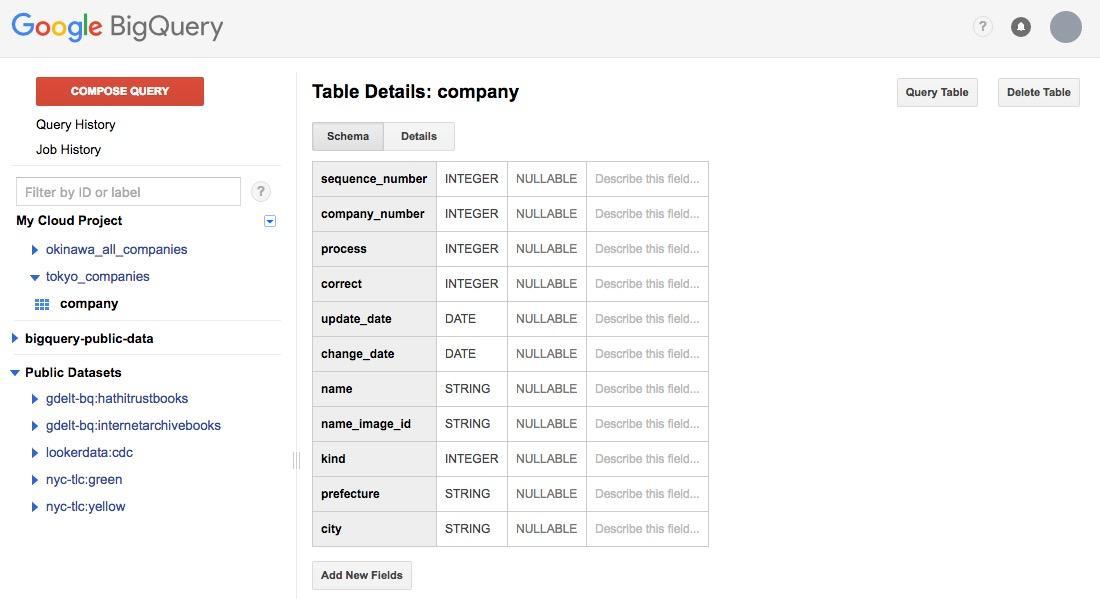
テーブルの作成が完了すると、テーブルの詳細が表示されます。この画面上で右上に表示されている [Query Table] をクリックすることで、クエリの実行画面に移動します。それでは、データに対してクエリを発行していきましょう。クエリの入力画面に以下のようにクエリを入力します。
SELECT count(name) FROM [プロジェクトID:tokyo_companies.company] WHERE city = "千代田区"
このクエリは千代田区にある会社の数を調べるクエリとなっています。
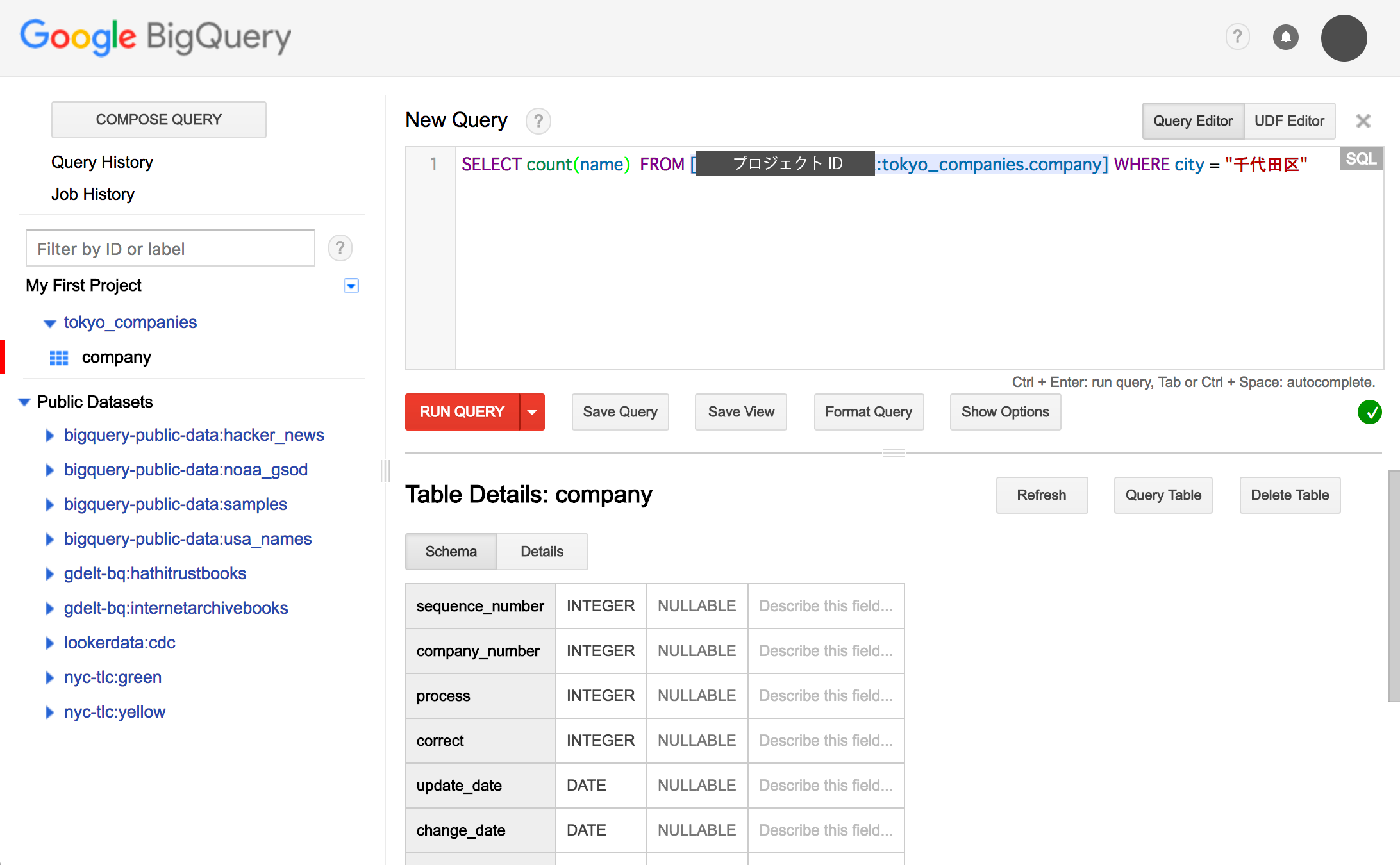
クエリが実行され、数が表示されたかと思います。
このファイルに含まれる行数はは記事執筆時点では約97万行、千代田区の法人数は65655行でした。約88秒程度で結果が返ってきました。このように、大きな CSV ファイルに対して SQL でクエリを実行し、結果を受け取ることができました。
次に、もう少し複雑な集計を行ってみましょう。東京都の97万の法人を区ごとにカウントし、どの区にいくつ法人があるかを表示します。
クエリ入力画面に以下のようにクエリを入力します。
SELECT city, count(company_number) AS company_number FROM [プロジェクトID:tokyo_companies.company] GROUP BY city ORDER BY company_number DESC
[RUN QUERY] をクリックするとクエリが実行されます。
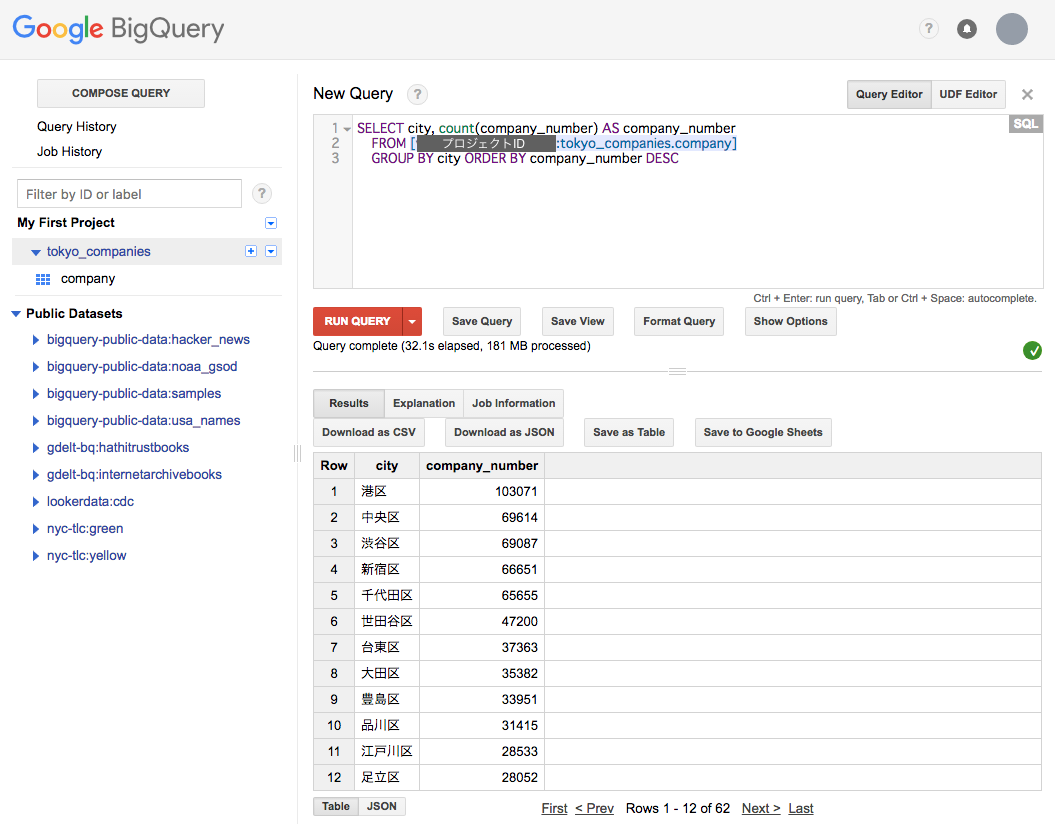
上の画面のように、法人数の多い順に区が表示されます。このクエリでは約30秒程度で結果が返ってきました。このように、普通の SQL 文で集計をする感覚で、気軽にビッグデータの集計作業が行えます。
おわりに
いかがでしたでしょうか。簡単にデータの解析ができることに驚かれたのではないでしょうか。このように BigQuery を使えば簡単にデータを取り込み、 SQL を使ってデータの集計作業を行うことが可能となります。
【関連記事】
超高速でデータ分析できる!専門知識なしで扱えるGoogle BigQueryがとにかくスゴイ!
BigQueryで考慮すべきセキュリティとその対策を一挙ご紹介!
弊社トップゲートでは、Google Cloud (GCP) 利用料3%OFFや支払代行手数料無料、請求書払い可能などGoogle Cloud (GCP)をお得に便利に利用できます。さらに専門的な知見を活かし、幅広くあなたのビジネスを加速させるためにサポートをワンストップで対応することが可能です。
Google Workspace(旧G Suite)に関しても、実績に裏付けられた技術力やさまざまな導入支援実績があります。あなたの状況に最適な利用方法の提案から運用のサポートまでのあなたに寄り添ったサポートを実現します!
Google Cloud (GCP)、またはGoogle Workspace(旧G Suite)の導入をご検討をされている方はお気軽にお問い合わせください。
メール登録者数3万件!TOPGATE MAGAZINE大好評配信中!
Google Cloud(GCP)、Google Workspace(旧G Suite) 、TOPGATEの最新情報が満載!