こんなに簡単にできるの? Google Cloud (GCP)を活用した時系列分析のやり方を徹底解説!
- BigQuery ML
- Cloud
- Google Cloud Day
- 時系列分析
本記事は、2021年5月27日に開催された Google の公式イベント「 Google Cloud Day : Digital ’21 」において、 Google Cloud カスタマーエンジニアの葛木美紀氏が講演された「 Google Cloud で時系列分析を試してみた-ベストなソリューションは?-」のレポート記事となります。
今回は Google Cloud (GCP)を活用した時系列分析のやり方を詳しく解説しています。
なお、本記事内で使用している画像に関しては Google Cloud Day : Digital ’21 「 Google Cloud で時系列分析を試してみた-ベストなソリューションは?-」を出典元として参照しております。
それでは、早速内容を見ていきましょう。
時系列データとは?
時系列分析について考えるためには、はじめに時系列データを正しく理解する必要があります。
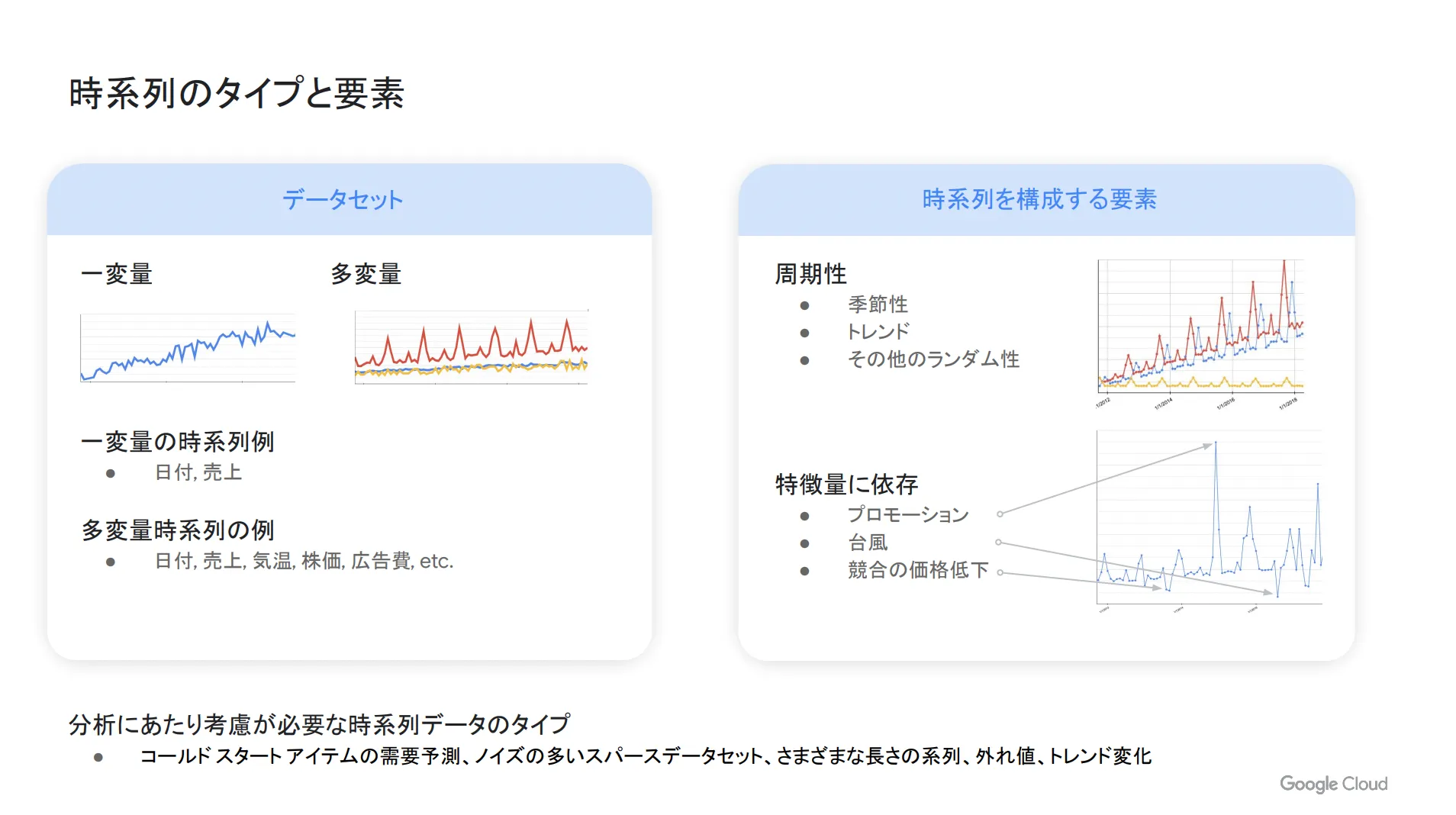
時系列データとは、時間の経過とともに定点観測されたデータのことであり、代表的な例としては株価、気温、売上金額などが挙げられます。これらは時間の流れに合わせて順番に並べられるデータであり、その順番自体が重要な意味を持っています。そのため、時系列データは「データの順番を並び替えることはない」という特徴を持っています。
大きく分類すると、時系列データは以下の2種類に分けられます。
| 種別 | 概要 | 例 |
|---|---|---|
| 一変量 | 1つの時系列のみで構成されているデータ | 日付、売上 |
| 多変量 | 2つ以上の時系列で構成されているデータ | 日付、売上、気温、株価、広告費など |
また、時系列データの構成要素としては「季節性」と「トレンド」があります。季節性は日付や曜日など一定の周期ごとに発生するパターンのことであり、トレンドは過去データから予測される数値傾向のことです。加えて、その他の変動要素を「ランダム性」として時系列データに組み込むこともあります。
時系列分析とは?
時系列分析とは、時系列データを分析することで得られた傾向や特徴から、将来の姿を予測するための分析手法です。時系列分析には様々なアプローチがあり、複数のモデルが存在します。
以下、代表的な時系列分析のモデルを表にまとめます。
| モデル | 概要 |
|---|---|
| AR モデル | 自己回帰モデルと呼ばれており、過去データを基に将来の値を予測する |
| MA モデル | 移動平均モデルと呼ばれており、為替データなどのテクニカル指標で使われるケースが多い |
| ARMA モデル | AR モデルと MA モデルを組み合わせたモデル |
| ARIMA モデル | ある時点のデータとその直近の値との関係性を分析し、それらの関係性が維持されるという仮定で将来の値を予測する |
このように、時系列分析には様々なアプローチが存在します。細かい説明は割愛しますが、自社の目的や扱うデータに合わせて、最適な分析手法を選択することが大切です。
時系列分析の課題
時系列分析には様々な手法がありますが、今回は ARIMA モデルに注目してご説明します。
ARIMA モデルは AutoRegressive Integrated Moving Average の略であり、自己回帰を活用したモデルの一種です。ある時点のデータとその直近の値との関係性を分析し、それらの関係性が維持されるという仮定で将来の値を予測します。
ARIMA モデルでは、以下3つの変数を利用します。
- 自己回帰( p ):モデル内の自己回帰の次数
- 差分( d ):観測値の差分の次数
- 移動平均( q ):モデル内の移動平均の次数
ARIMA モデルについて細かい内容を理解する必要はありませんが、大切なことは上記3つの変数を決定するために工数が掛かる点です。例えば、単位根検定、自己相関関数、偏自己相関、残差分析などのヒューリスティックなルールを用いて、人間が毎回変数を決定しなければいけません。
このように、 ARIMA モデルによる時系列分析は時間と手間が発生するため、生産性の観点において課題が残されていました。そして、この課題を解決するためには Google Cloud (GCP)のサービスが有効なソリューションになります。
Google Cloud (GCP)とは?
Google Cloud (GCP) は Google が提供しているパブリッククラウドサービスです。同じ種別のサービスとしては、 Microsoft 提供の Azure や Amazon 提供の AWS などが挙げられます。
Google Cloud (GCP) は 「 Gmail 」や「 YouTube 」などの有名サービスで実際に動いているプラットフォーム技術をそのまま使用でき、非常に高いインフラ性能を誇ります。コンピューティングやストレージをはじめ、様々な機能が搭載されています。
この Google Cloud (GCP)に内包されている BigQuery ML や AutoML Forecasting を活用することで、手間なく時系列分析を行うことができます。次章以降で具体的なやり方をご説明します。
Google Cloud (GCP)については、以下の記事で詳しく解説しています。
クラウド市場が急成長中?数あるサービスの中でGCPが人気の理由5選!
BigQuery ML を活用した時系列分析のやり方
BigQueryとは Google Cloud (GCP)で提供されているビッグデータ解析サービスです。通常では長い時間かかるクエリを数 TB (テラバイト)、数 PB (ペタバイト)のデータに対し数秒もしくは数十秒で終わらせることができます。
BigQuery はクラウドで提供されているため、サーバーレスでスケーラビリティがあり、非常にコストパフォーマンスに優れています。他の多彩な Google Cloud (GCP)の提供するサービスともシームレスに連携もでき、扱いやすいサービスの一つです。
この BigQuery には BigQuery ML (以下、 BQML と記載)という機械学習機能が組み込まれており、 BQML を活用することで手間なく時系列分析を行うことができます。
通常、機械学習モデルを作成するためには、様々な場所からデータを移動して加工する必要がありますが、 BQML は BigQuery 上のデータをそのまま SQL で処理できるため、生産性が大きく向上します。専門的な知識は必要なく、簡単な SQL で手軽にモデルを作成できる点も嬉しいポイントです。
BQML では以下のモデルがサポートされており、分類や回帰だけでなく、今回ご紹介する時系列分析を行うことも可能となっています。
| 分類 | ・ロジスティック回帰 ・DNN 分類 ( TensorFlow ) ・XGBoost ・AutoML Tables |
| 回帰 | ・線形回帰 ・DNN 回帰 ( TensorFlow ) ・XGBoost ・AutoML Tables |
| その他のモデル | ・時系列予測( ARIMA ) ・k-means クラスタリング ・リコメンデーション: Matrix factorization |
| モデルのインポート・エクスポート | ・バッチおよびオンライン予測用 TensorFlow モデル |
それでは、実際に BQML を使ってモデルを作成するやり方をご説明します。
今回は酒店の販売データを例にとり、お酒が販売された日付、販売されたお酒の種類、販売数などの過去データを基にして、将来の需要を予測するようなモデルを作成します。
トレーニング用データの成形
はじめに機械学習(トレーニング)に使うためのデータを成形します。
サンプルとして、以下の SQL 文を記述してください。
CREATE OR REPLACE TABLE bqml.training_data
AS
SELECT
date,
item_description AS item_name,
SUM(bottles_sold) AS total_amount_sold
FROM
bigquery-public-data.iowa_liquor_sales.sales
GROUP BY
date, item_name
HAVING
date BETWEEN DATE('2016-01-01') AND
DATE('2017-06-01')
今回のトレーニングデータは「 bqml.training_data 」という名称で保存しました。「 SELECT 」の部分で日付、商品名、販売本数の3つの列を選択し、「 HAVING 」の部分では 2016年1月1日から2017年6月1日までの情報をトレーニング用のデータとして指定しています。
テーブルの作成
データ成形後に「実行」ボタンを押すと、新しいデーブルが自動的に作成されます。このとき、テーブルの名前は自身が準備したトレーニングデータの名前と同一になります。
なお、 BQML はローカル線型保管という手法を採用しており、これによりデータの日付情報を自動的に保管してくれます。そのため、仮にテーブル内のデータの日付情報が欠けている場合でも問題ありませんし、人間が日付情報を個別管理する必要がないため、業務効率化にも繋がります。
トレーニングモデルの SQL 記述
テーブル作成後、トレーニングモデルの SQL を記述します。
サンプルとして、以下の SQL 文を記述してください。
CREATE OR REPLACE MODEL
bqml.forecast_by_product
OPTIONS(
MODEL_TYPE='ARIMA_PLUS',
TIME_SERIES_TIMESTAMP_COL='date',
TIME_SERIES_DATA_COL='total_amount_sold',
TIME_SERIES_ID_COL='item_name',
HOLIDAY_REGION='US'
) AS
SELECT
date,
item_name,
total_amount_sold
FROM
bqml.training_data
ざっくり、上からコードの意味を解説します。
「 CREATE OR REPLACE MODEL 」の部分には「 bqml.forecast_by_product 」と記述されていますが、これは bqml というデータセットの中に forecast_by_product という名前のモデルを作る、という指定になります。
次に「 OPTIONS 」の部分では、モデルタイプとして ARIMA モデルを選択し、対象となる3つのカラムを指定しています。ここで「 item_name 」という記述がありますが、 BQML ではデータ内の商品名ごとに複数の時系列モデルを使ってトレーニングを実行できます。そのため、製品ごとに個別の時系列モデルをトレーニングする必要はありません。「 HOLIDAY_REGION 」は季節性に関連する記述であり、特定地域における休日を考慮してトレーニングを実行してくれるものです。なお、 HOLIDAY_REGION のオプションを使うためには、最低1年分のデータが必要になります。
最後に「 SELECT 」の部分ですが、これは特定データに対する選択カラムを指定する箇所であり、今回の場合は「 bqml.training_data 」という名称のデータに対して3つの選択カラムを指定しています。
モデルの生成
SQL の記述が完了したら「実行」ボタンを押して、モデルを作成します。
BQML は個々の商品の時系列ごとに最大42パターンのモデルを作成し、 AIC という指標により最適なモデルを自動的に判別してくれます。そのため、他の BQML モデルよりも実行時間が長くなっており、今回の例では1時間ほどを要する可能性もあります。
SQL の実行が完了すると、商品ごとに最適なモデルが返されます。
以下、具体的なモデルのイメージです。商品別に季節性や休日などが考慮されたモデルが表示されています。

なお、これらのモデルは BigQuery の画面から直接確認することも可能です。
予測の実行
最後に、作成したモデルを基に予測を行います。
サンプルとして、以下の SQL 文を記述してください。
SELECT
*
FROM
ML.FORECAST(MODEL bqml.forecast_by_product,
STRUCT(30 AS horizon,
0.90 AS confidence_level)
「 ML.FORECAST 」の部分で作成したモデルを指定して「 STRUCT 」の部分でパラメータを指定します。「 horizon 」は将来予測する次点の数であり、今回の場合は30日分の予測を行うように指定しています。「 confidence_level 」は信頼区間を意味するパラメータです。
予測の完了
SQL を実行して予測が完了すると、以下のように予測結果が表示されます。
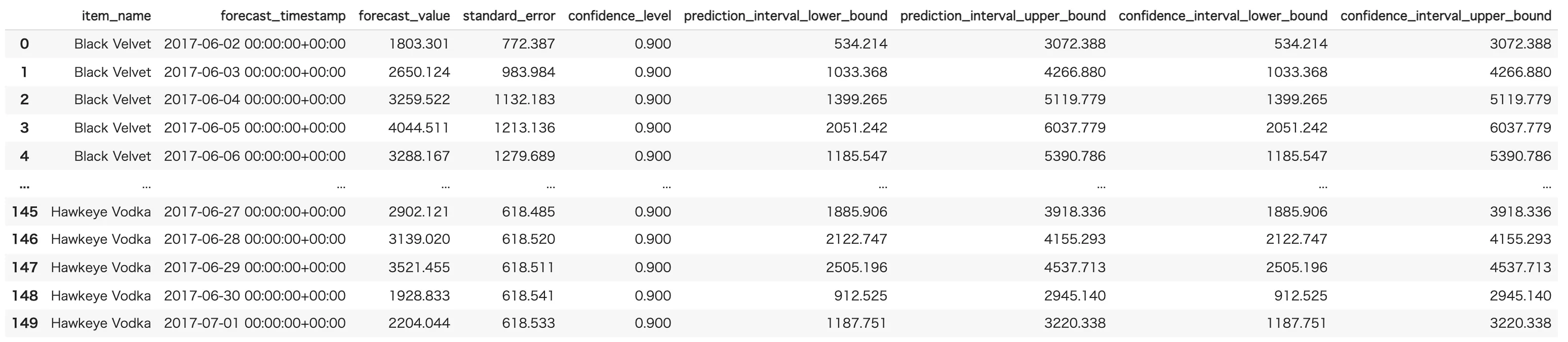
以上で BigQuery ML を活用した時系列分析は完了です。このように、簡単な SQL を使うだけで手間なく時系列分析を進めることができます。
AutoML Forecasting を活用した時系列分析のやり方
AutoML Forecasting による時系列分析は Deep Learning を活用します。 Auto ML とは BigQuery とはまったく異なるサービスであり、ファイルをアップロードすることで機械学習モデルを作ってくれるものです。コーディングが一切不要な点が大きな特徴です。
AutoML Forecasting はニューラルネットワークのアプローチで時系列分析を行うため、 ARIMA モデルでは扱えないような大規模なデータや不規則な傾向が含まれている場合に最適な選択肢になります。特徴量の前処理やハイパーパラメーターチューニングなどを自動で行ってくれる点も嬉しいポイントです。
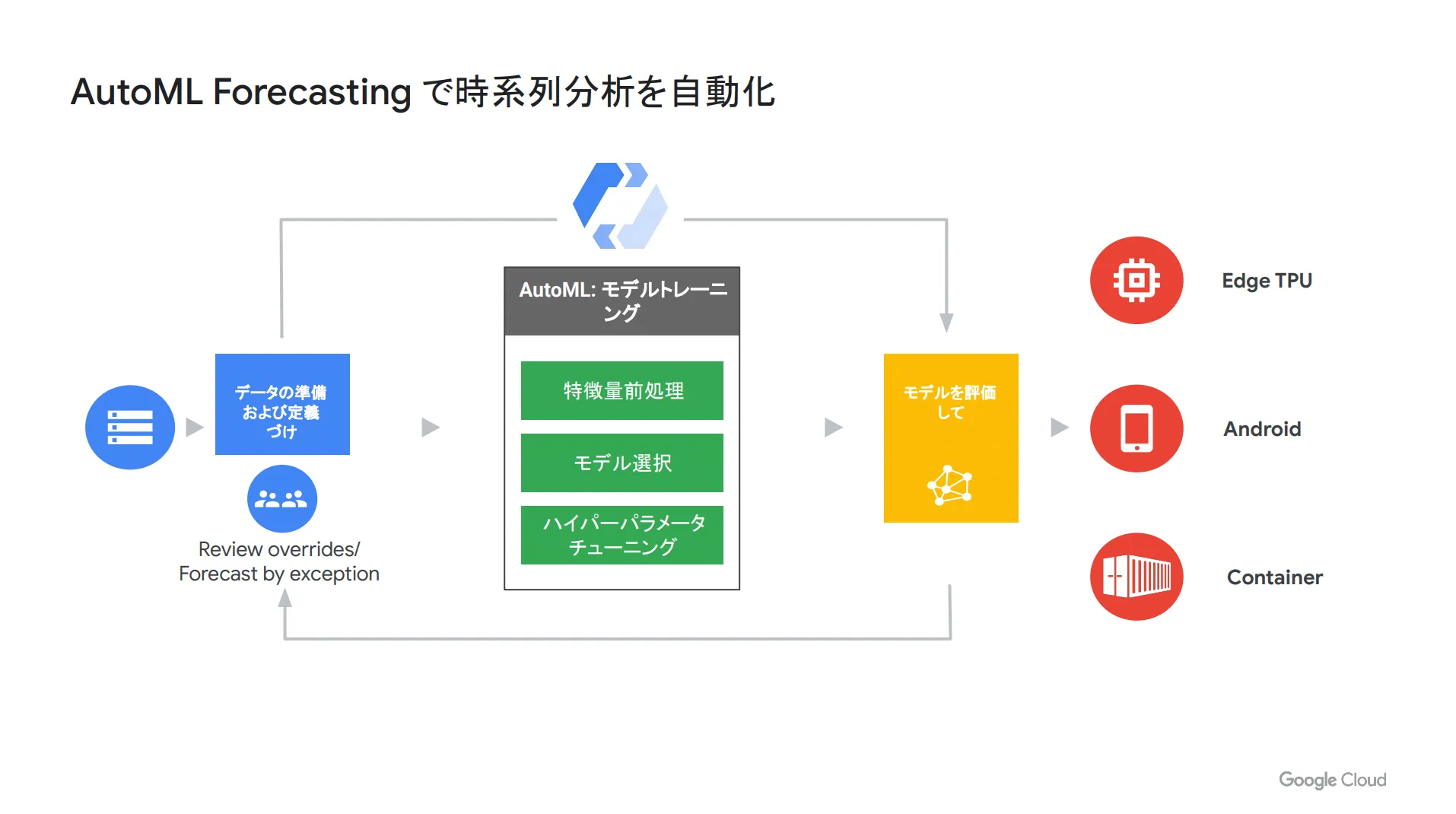
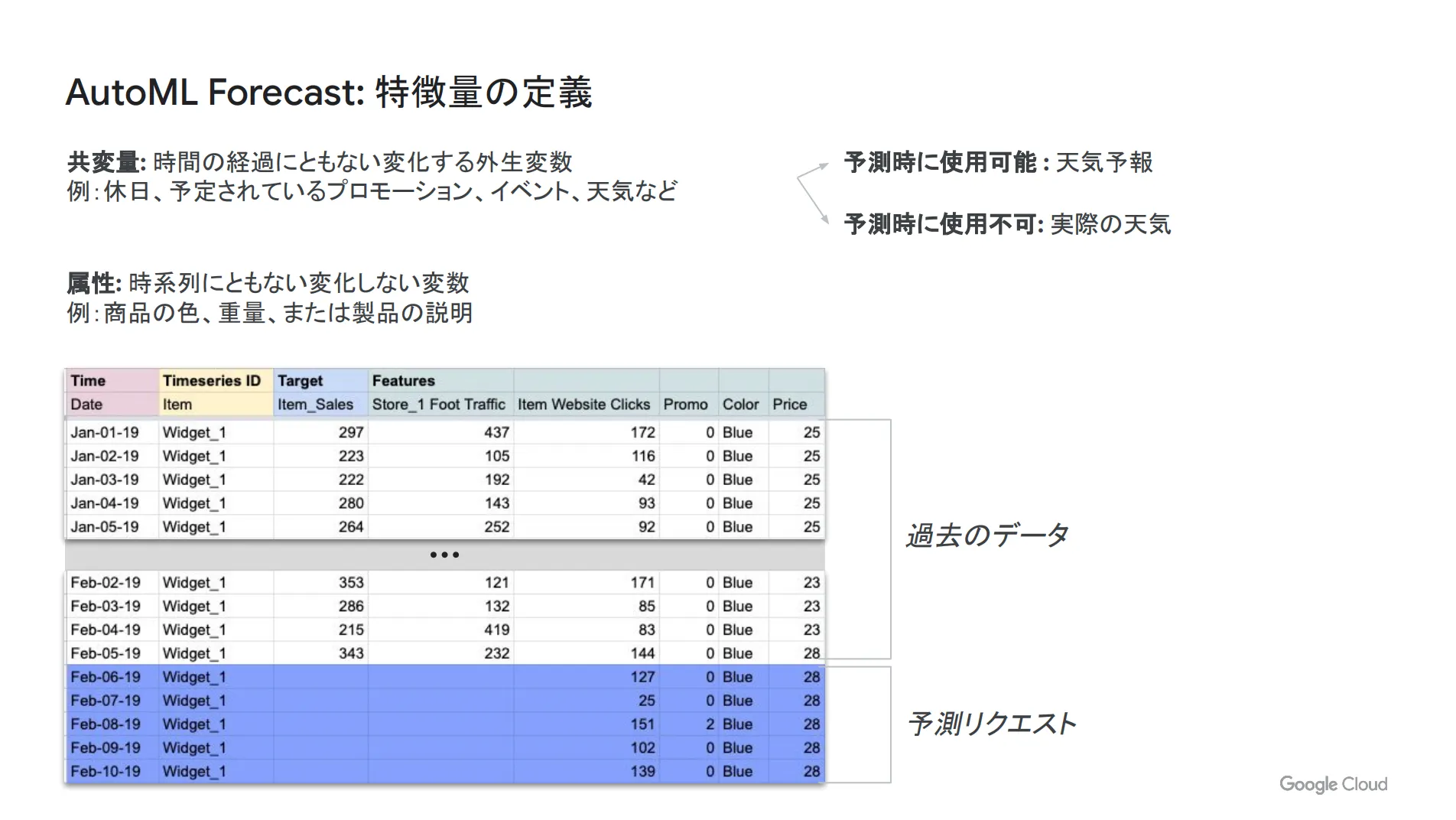
また、特徴量以外にも以下のような様々なデータを前処理して、自動的に最適な形に変換します。

特徴量の定義としては、共変量という時間に依存し、かつ予測値に影響を与える項目を設定可能です。代表的な例としては天気などが挙げられます。また属性というパラメータには、時間に依存せず、予測値に影響を与える項目を設定できます。
ここからは、 AutoML Forecasting による分析のやり方をご紹介します。
データセットの作成
はじめに AutoML でデータセットを作成します。
以下が AutoML のデータセット作成画面のコンソールです。まずは「作成」ボタンを押します。
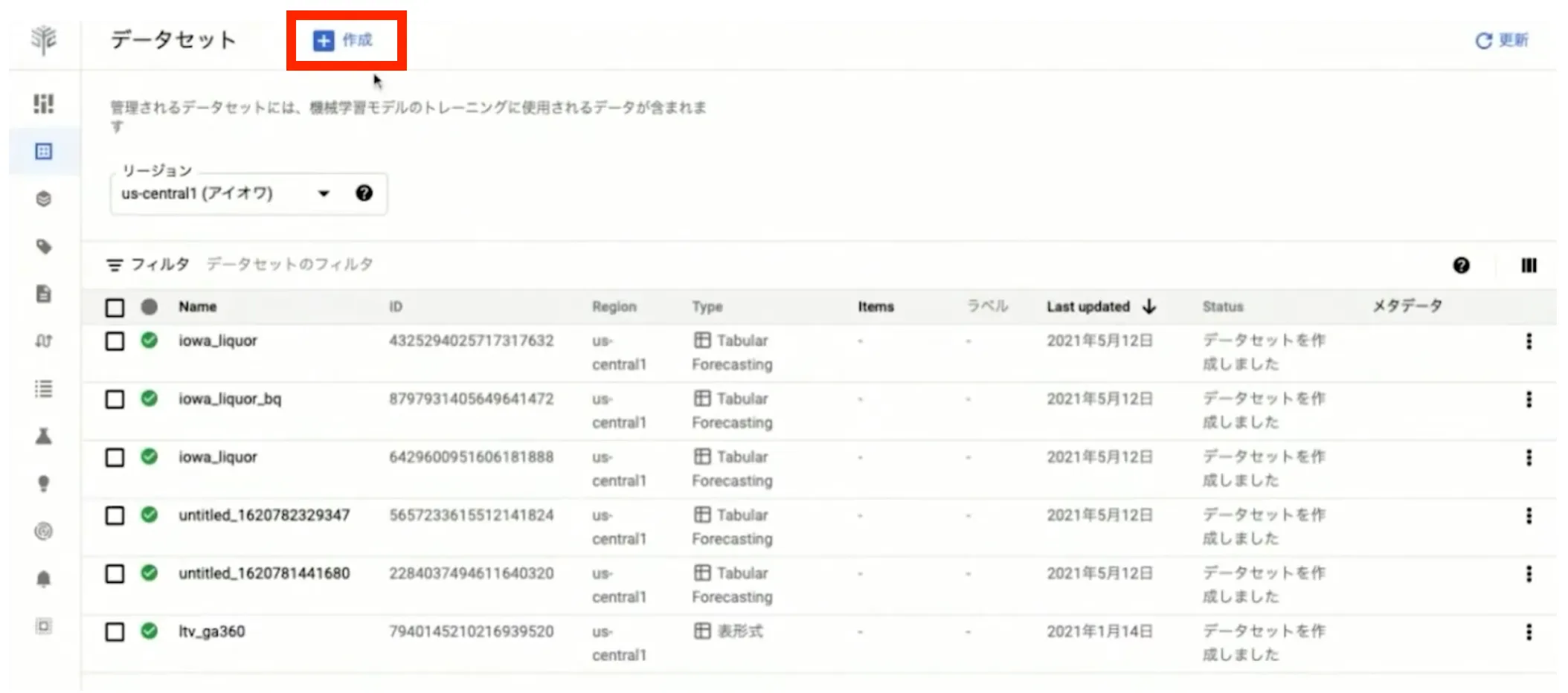
次に任意のデータセット名を入力し、「データタイプと目標の選択」の部分はそれぞれ「表形式」と「予測」を選択します。最後に最下部の「作成」ボタンを押してデータセットの作成は完了です。
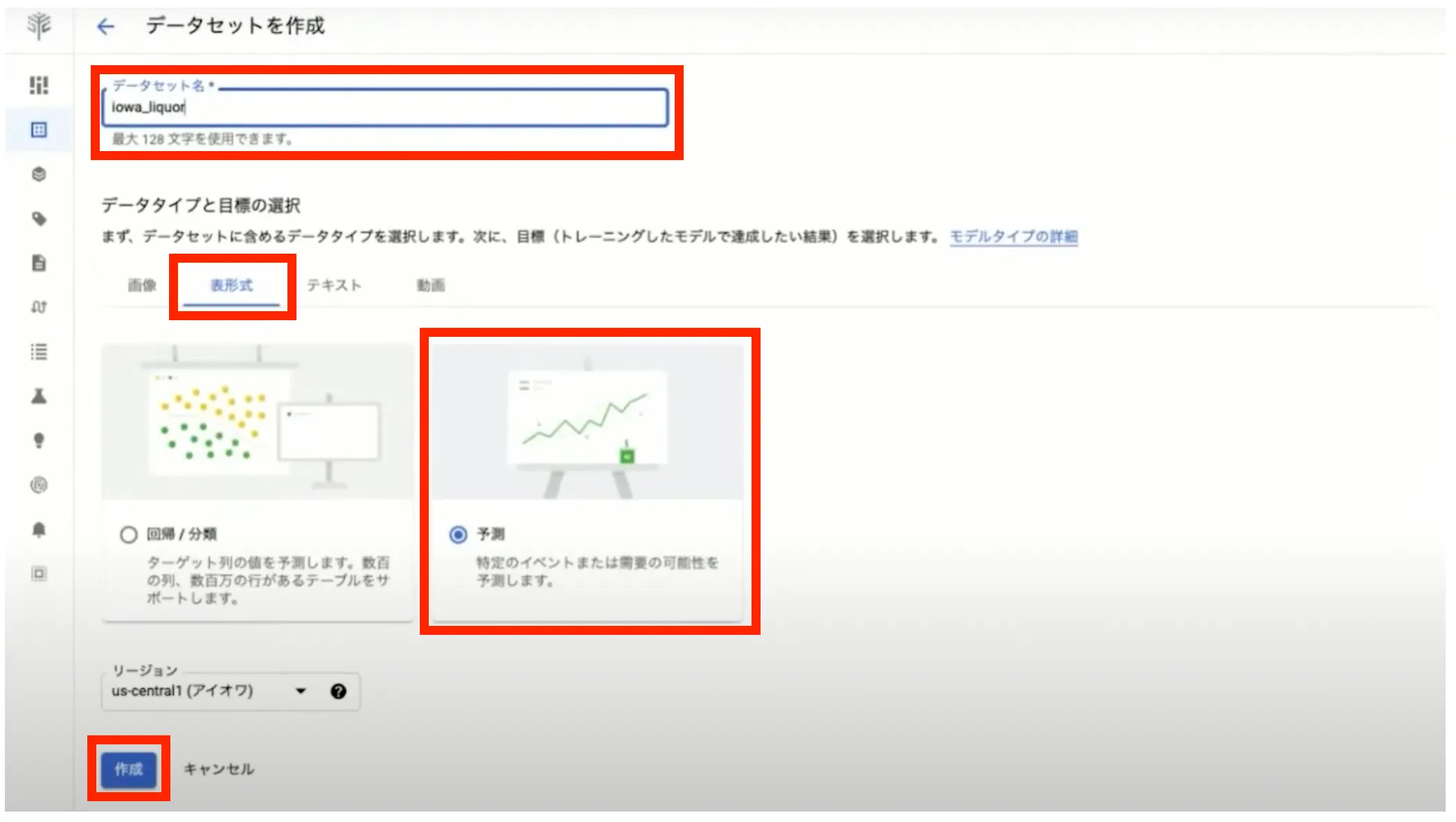
データセットの取り込み
データセット作成が終わるとデータセットの取り込み画面に遷移します。データソースは CSV ファイルや BigQuery から指定が可能となっていますが、今回は前述したトレーニング用データ「 bqml.training_data 」を指定しています。データソースを指定後、「続行」ボタンを押してデータセットの取り込みを開始します。
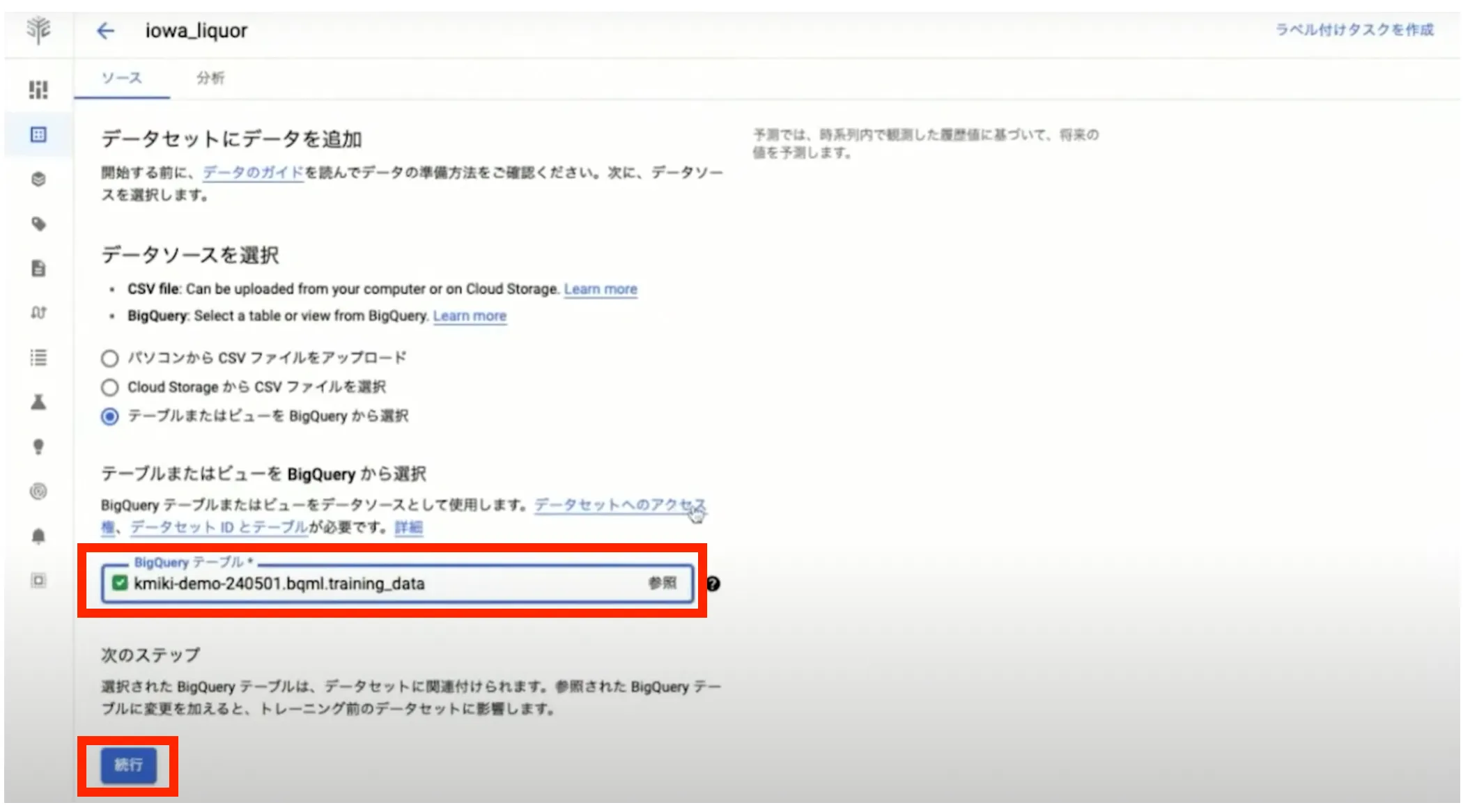
分析情報の設定
データセットの取り込み後、分析情報の設定を行います。「時系列の識別子列」に商品名( item_name )を選択し、「タイムスタンプ列」に date を選択します。選択が終わったら「新しいモデルをトレーニング」ボタンを押してトレーニングの設定画面に遷移します。
トレーニングの設定
トレーニングの設定では、はじめにトレーニング方法を選択します。「 AutoML 」を選択して「続行」ボタンを押します。
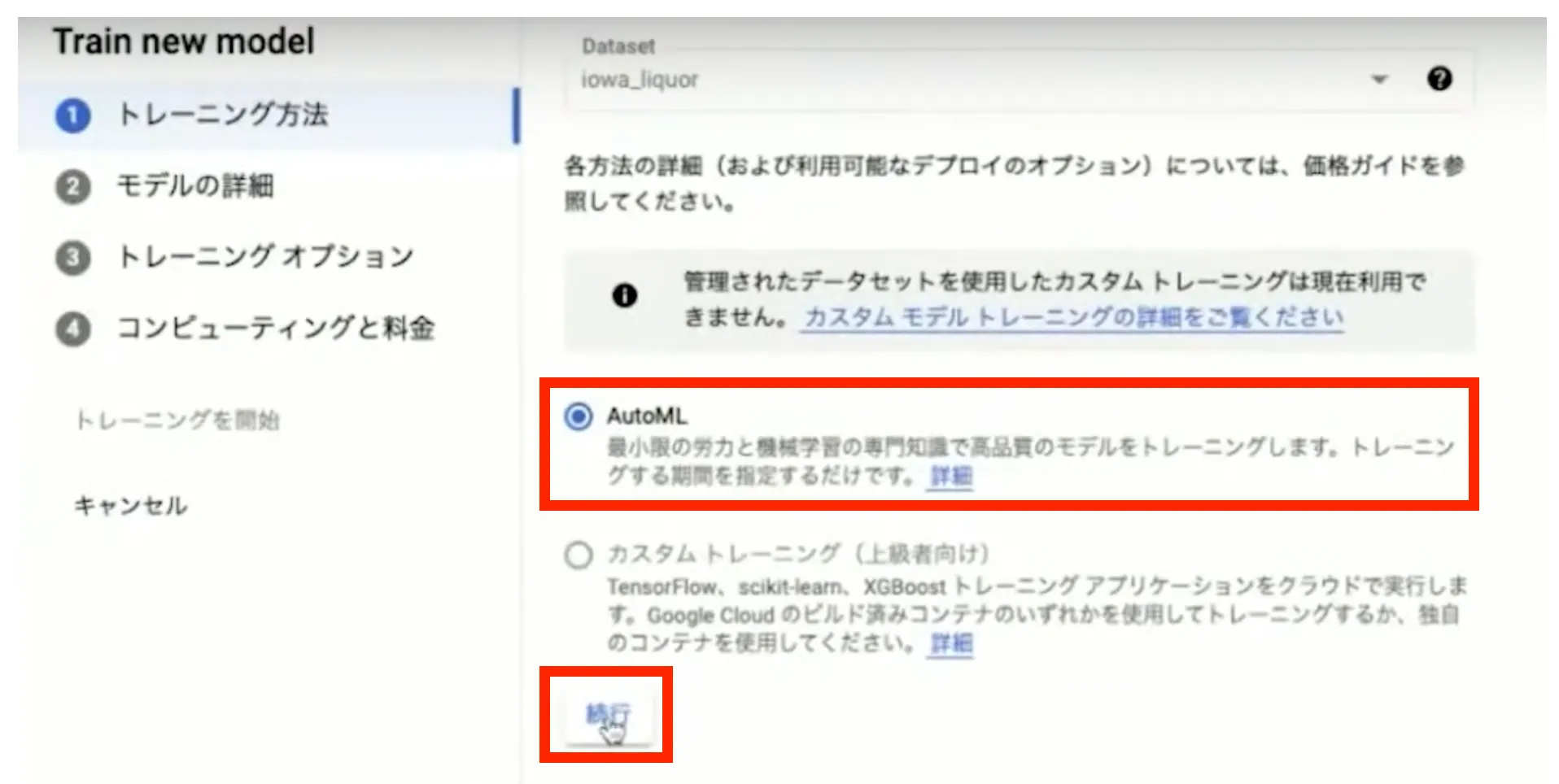
次にモデルの詳細設定を行います。「 Target column 」には予測したい対象を選択するため、今回は販売本数( total_amount_sold (INTEGER) )を選びます。「データの粒度」は日付ごとにデータを取得するように Daily を選択します。
その下の「 Forecast horizon 」と「コンテキスト期間」にはどちらも7を入力します。これは「過去7日間のデータから7日分の未来の値を予測する」という設定を行っています。すべての設定が完了したら最下部の「続行」ボタンを押します。
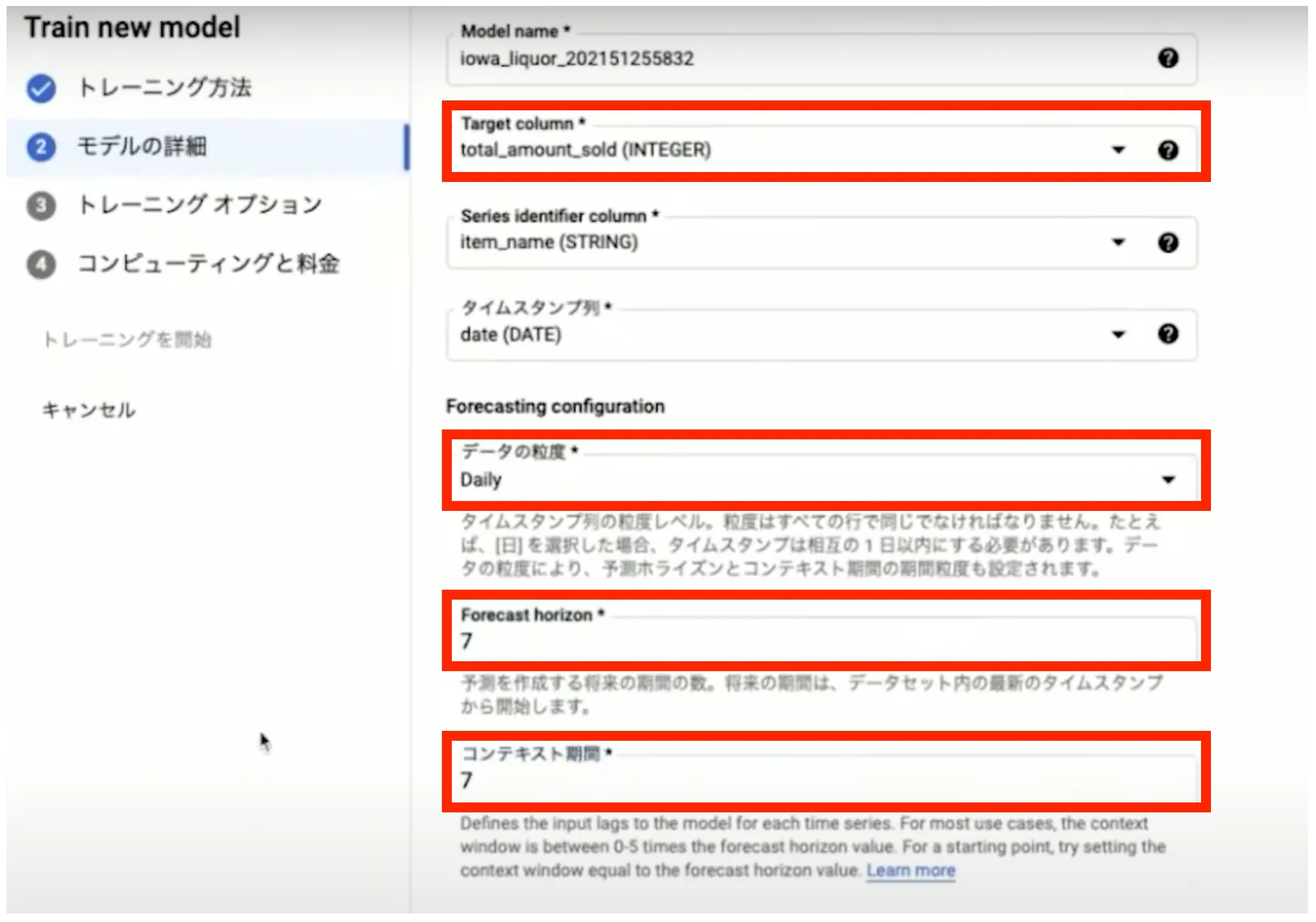
トレーニングオプションでは特に設定を行う必要はありません。内容を確認して「続行」ボタンを押します。
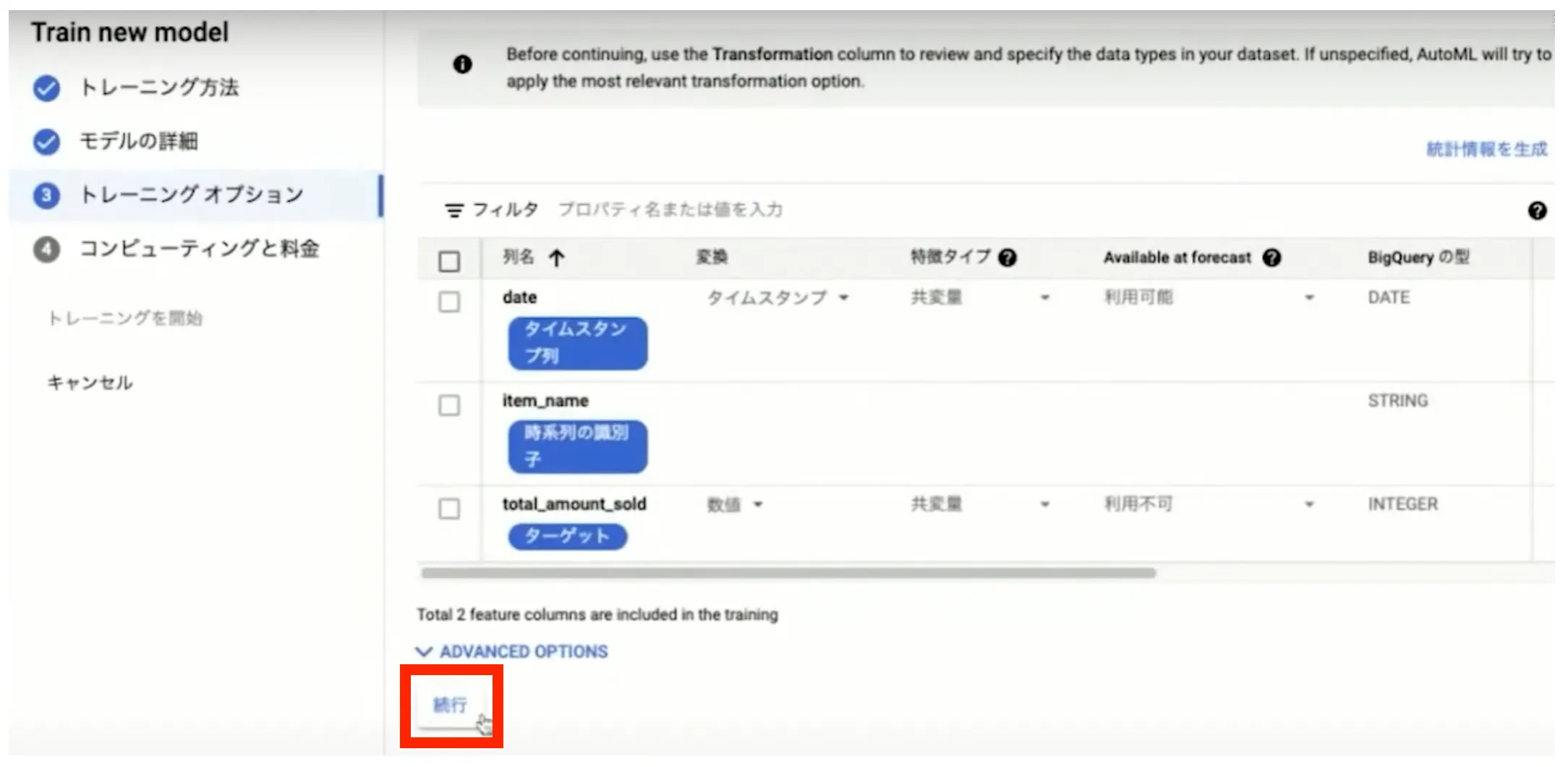
最後にモデルのトレーニングに費やすノード時間の最大値を入力します。今回は1ノード時間でトレーニングを開始するように設定しています。以上でトレーニングの設定は完了であり、「トレーニングの開始」を押すとトレーニングが開始されます。
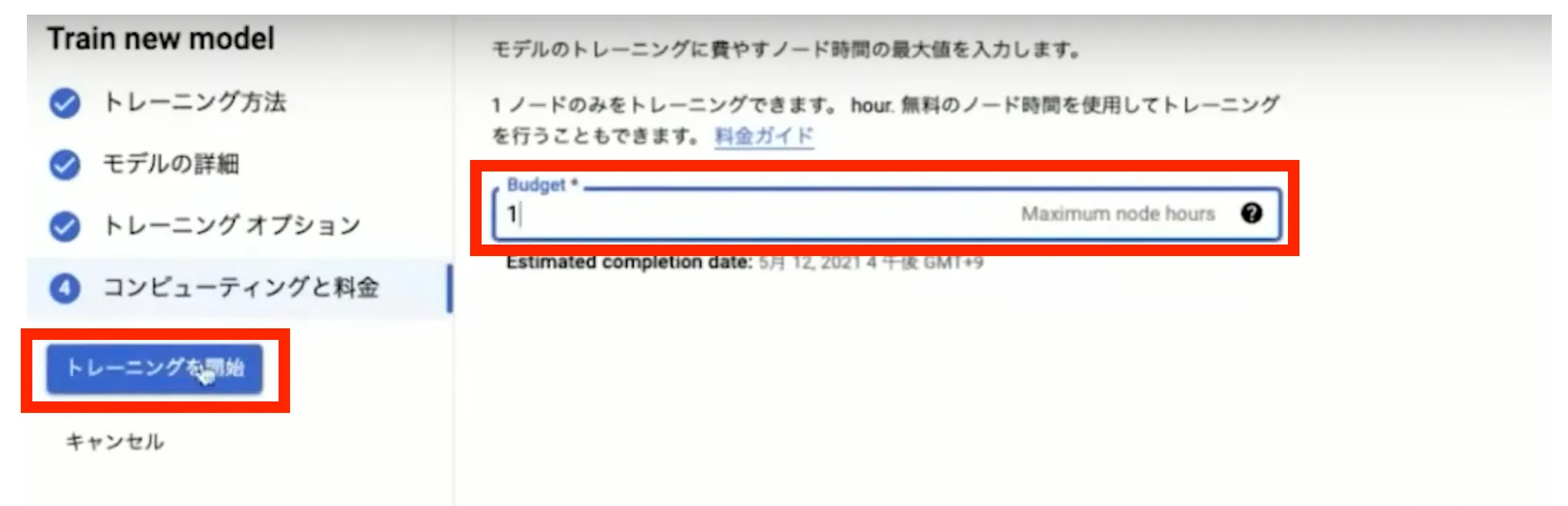
予測の実行
トレーニング終了後、完成したモデルが画面上に表示されます。
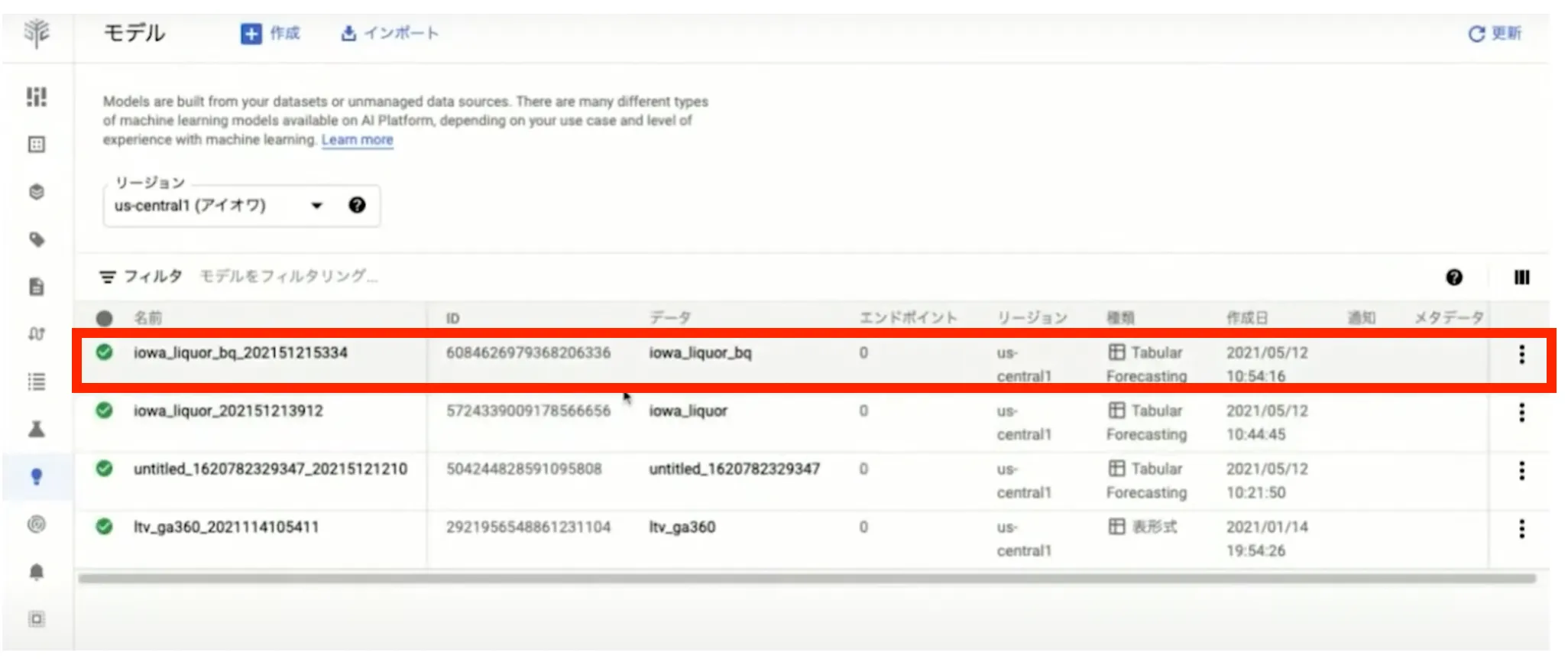
そして、対象のモデルをクリックするとモデルの指標が表示されます。
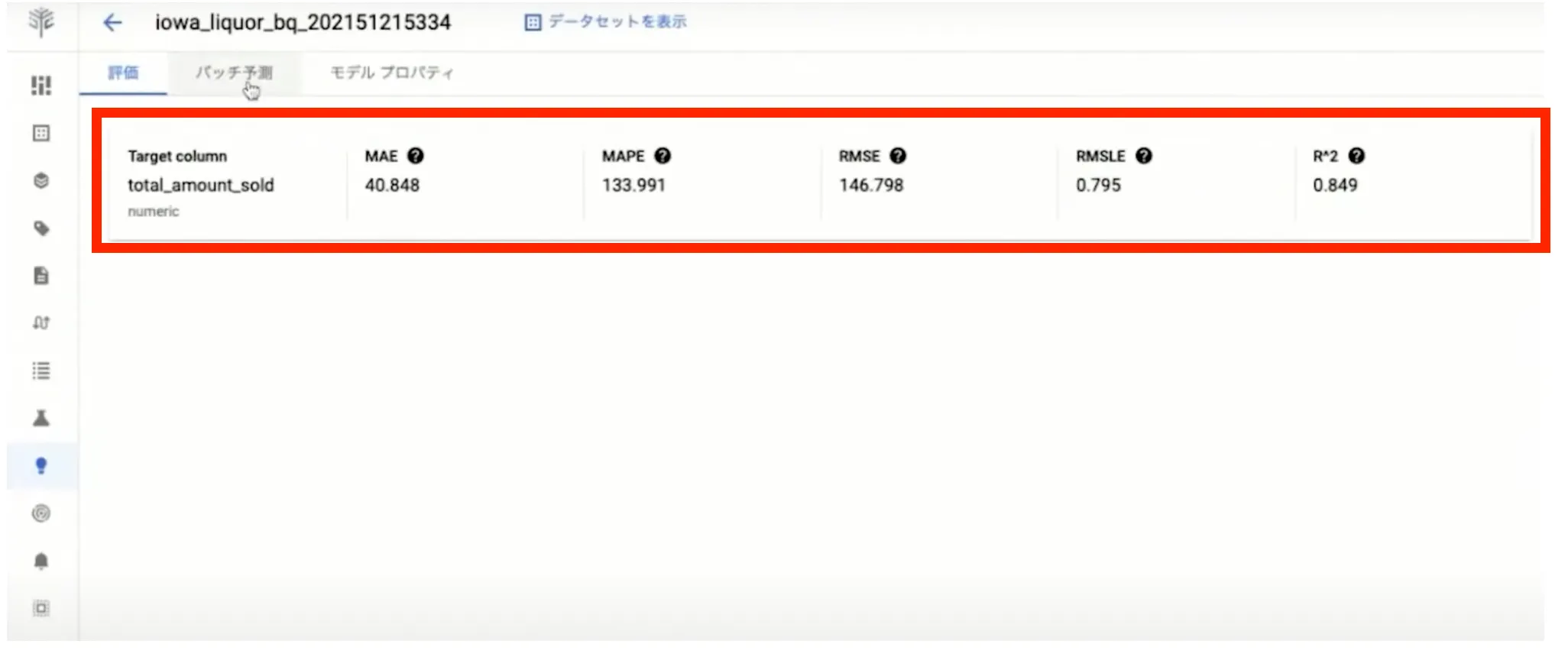
このとき、 BigQuery にテストデータのエクスポートを行うことができ、そのモデルを使った場合の予測結果を確認できます。
例えば、下図の赤枠部であれば、2017年4月17日の商品販売本数の予測結果(9.3138.....)と実際の販売実績(7)を比較しながら表示することが可能です。
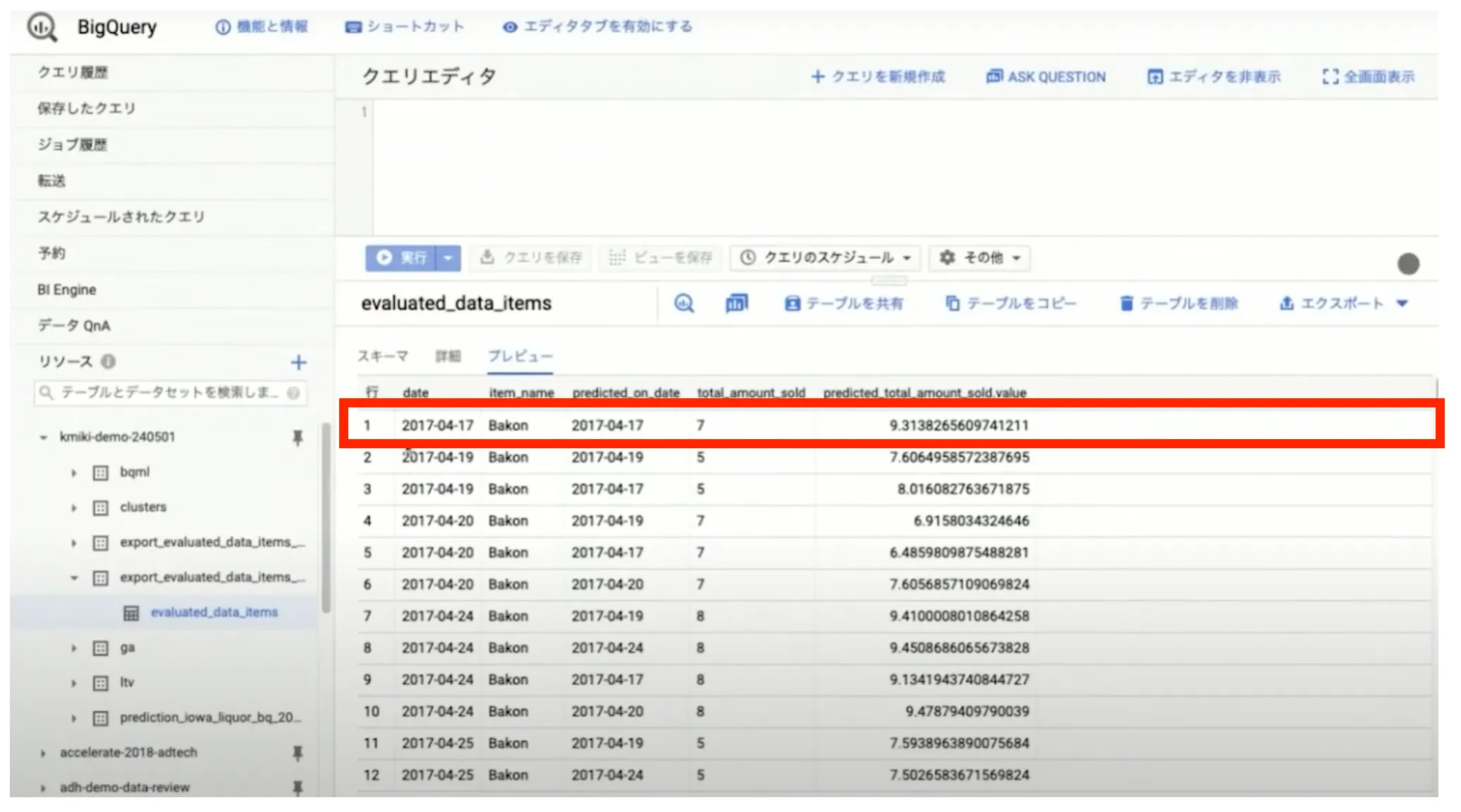
また、バッチ予測という機能を使えば、 BigQuery ではなく Cloud Storage 上の CSV ファイルを使用して予測を実行することも可能です。
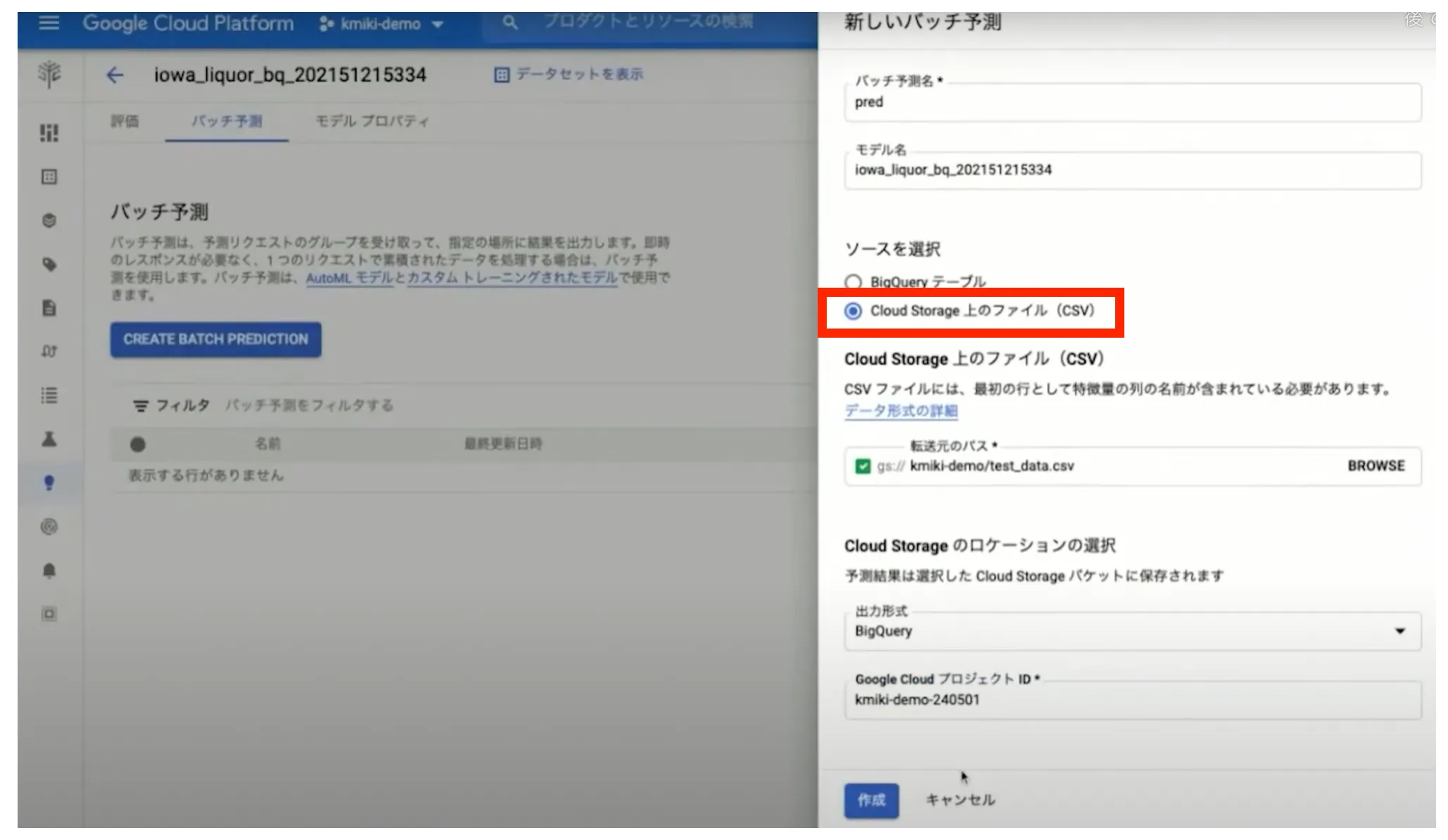
予測結果は BigQuery のプロジェクトに表示され、表示形式は BigQuery をデータソースとした場合と同一になります。
以上で AutoML Forecasting による時系列分析は完了です。このように、コードを書くことなく簡単な操作だけで時系列分析を進めることができます。
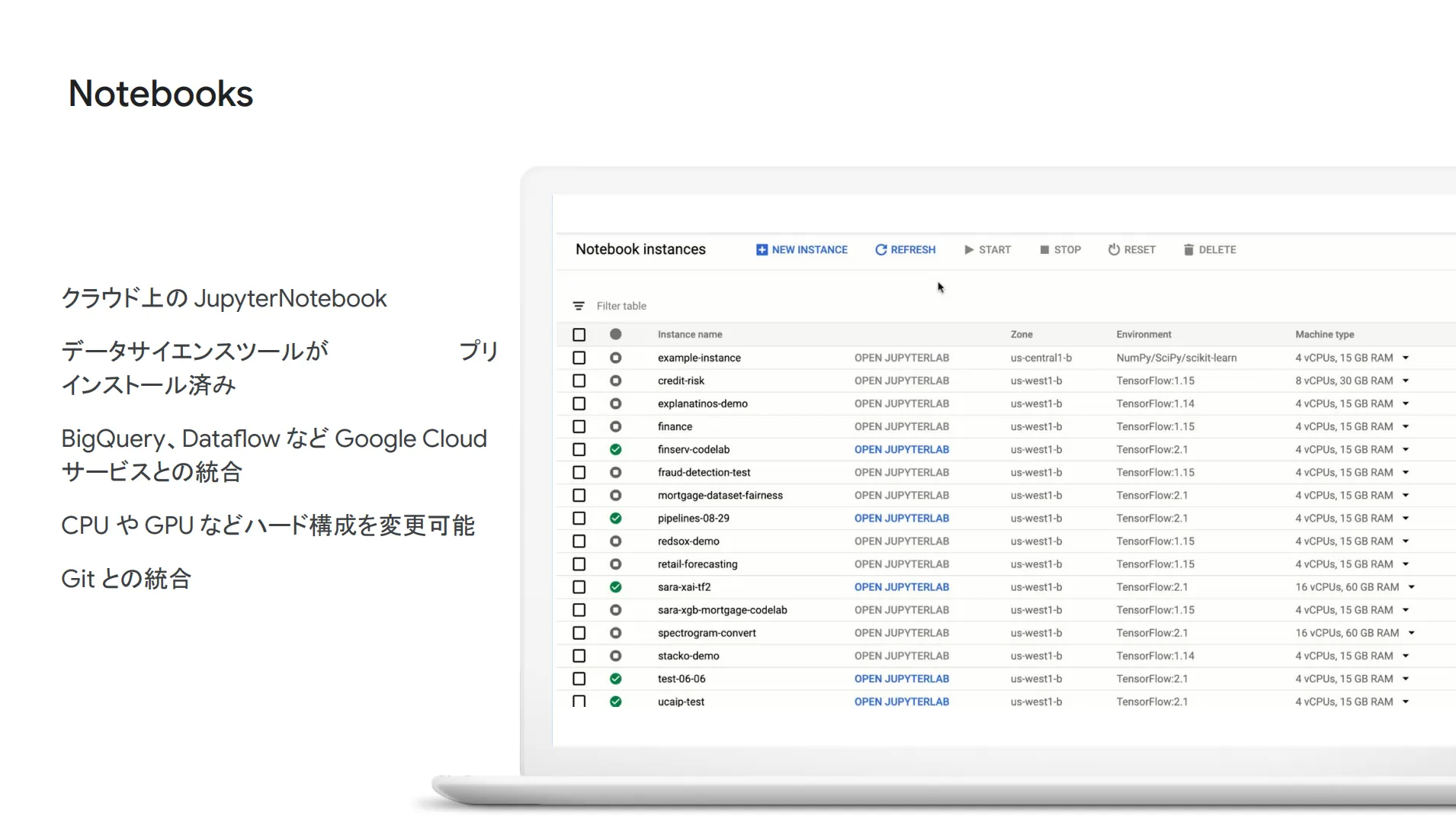
ちなみに、 AutoML Forecasting ではコードを使いませんでしたが、 Notebooks という製品を利用することで、一からコードを書いて時系列分析を行うことも可能です。一つの選択肢として覚えておいてください。
Google Cloud (GCP)を活用した時系列分析に関する質問
Q . AutoML Forecasting の料金はいくらですか?
A .料金はこちらを参照ください。
Q . BQML と AutoML の使い分けはどう考えれば良いですか?
A .共変量など、外部要因をモデルに取り込みたい場合は AutoML 、 SQL で迅速にモデルを作成したい場合は BQML という使い分けをしていただけます。
Q .1年以上のデータがないといけないのですか?
A .最低1000レコードが必要になります。詳しくはこちらを参照ください。
Q . Python から BigQuery ML の推論はできますか?
A . Python 用のクライアントライブラリや pandas との連携をご活用いただくことが可能です。
Q .季節性が検知された場合は、予測の際も季節性が考慮されるということですか?
A .ご理解の通りです。
Q . AutoML Forecasting は最低どれくらいの学習データが必要ですか?
A .1,000レコードが必要になります。
まとめ
本記事では、時系列分析の基礎的な内容から Google Cloud (GCP)を活用した時系列分析のやり方まで一挙にご紹介しました。
本来、時系列分析は大きな工数が発生する作業ですが、 Google Cloud (GCP)を使うことで、大幅に効率化できることをご理解いただけたのではないでしょうか。
今回は BigQuery ML による統計的手法と AutoML によるニューラルネットワークのアプローチをご紹介しましたが、これらは時系列分析ができるという点では共通しているものの、それぞれ異なる特徴を持っています。

それぞれの特徴を正しく理解して、自社の目的に合わせて最適なアプローチを選択してください。
なお、 BigQuery ML や AutoML は Google Cloud (GCP)に内包されているサービスであるため、利用には Google Cloud (GCP)の契約が必要になります。 Google との直接契約も可能ですが、弊社トップゲートで契約することで様々なメリットを享受できます。
Google との直接契約では営業担当が付かず、サービス契約後に細かい運用面の相談を行うことができません。一方トップゲートでは、専任の営業担当がアサインされるため、 Google Cloud (GCP)導入後のサポート体制も万全です。
弊社トップゲートは、2017年に Google Cloud (GCP)のプレミアサービスパートナー認定を取得しました。これは、 Google Cloud (GCP)のサービスパートナー制度の中で上位の位置付けとなる認定であり、豊富な実績と専門的な知識を有していることの証明になります。
時系列分析の作業自体は Google Cloud (GCP)で効率化できますが、実際に分析を行う際にはデータの成形方法やカラム指定など、細かい要素を考慮する必要があります。そのため、トップゲートのように専門性の高いパートナーと契約し、プロ目線の様々なアドバイスを受けることで、自社の分析効果を最大化することができます。
また、トップゲート経由で契約することで
- 請求書払いが可能
- 導入後サポートが充実
- Google Cloud ( GCP )の利用料金が3% OFF
など、様々なメリットを享受できます。
さらに、トップゲート自身が Google のサービスを自社で活用しているため、エンドユーザーの目線から、お客様の状況に合わせた最適な運用方法をご提案できます。 Google Cloud (GCP)を検討する際は、ぜひトップゲートへお気軽にお声がけください。
弊社トップゲートでは、専門的な知見を活かし、
- Google Cloud (GCP)支払い代行
- システム構築からアプリケーション開発
- Google Cloud (GCP)運用サポート
- Google Cloud (GCP)に関する技術サポート、コンサルティング
など幅広くあなたのビジネスを加速させるためにサポートをワンストップで対応することが可能です。
Google Workspace(旧G Suite)に関しても、実績に裏付けられた技術力やさまざまな導入支援実績があります。あなたの状況に最適な利用方法の提案から運用のサポートまでのあなたに寄り添ったサポートを実現します!
Google Cloud (GCP)、またはGoogle Workspace(旧G Suite)の導入をご検討をされている方はお気軽にお問い合わせください。
メール登録者数3万件!TOPGATE MAGAZINE大好評配信中!
Google Cloud(GCP)、Google Workspace(旧G Suite) 、TOPGATEの最新情報が満載!