BigQuery から Cloud Spanner に直接クエリを実行し、トランザクションデータをリアルタイムに分析しよう
- BigQuery
- Spanner
- トランザクションデータ
Google Cloud(GCP)は、サーバレスかつ大規模な初期投資が不要なデータウェアハウスのBigQuery と、トランザクションワークロード向けのリレーショナルデータベース Cloud Spanner を提供しています。現在のデータ分析では、既存のビッグデータ分析とともに、常に更新されるトランザクションデータベースのリアルタイム分析のニーズも高まっています。
本ブログでは、BigQuery からCloud Spanner への直接クエリを例に、メリットとデメリット、具体的な手順を解説します。
BigQuery とは
Google Cloud(GCP)には、インメモリ、非リレーショナル、リレーショナル、オブジェクト、ウェアハウスというデータを扱うためのデータベースポートフォリオがあります。オブジェクトストレージはデータレイクとして利用されることが多いため、ここではデータベースと一緒に並べています。
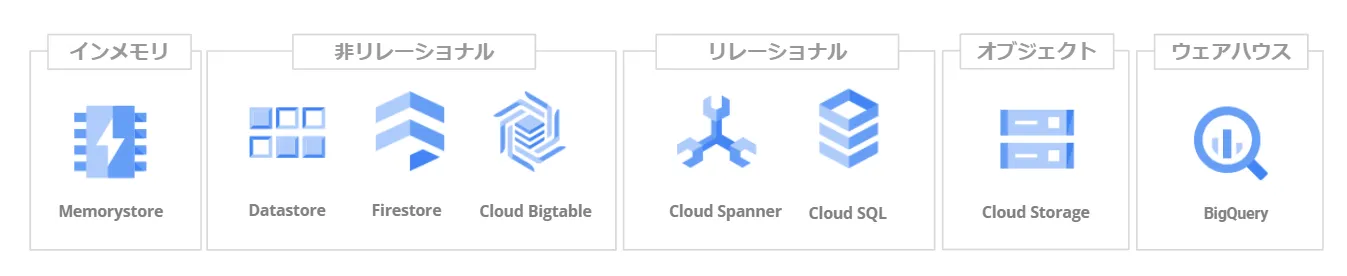
本ブログでは、この中のBigQuery とCloud Spanner を利用した分析方法について紹介します。BigQuery は、インフラを自前で構築、管理する必要のないフルマネージドのサービスであり、データを保管するストレージとSQLクエリエンジンの2つの機能で構成されています。SQLクエリエンジンとストレージは、高速なネットワークによって接続されており、機能の分離を実現しています。
これにより、ストレージ機能は、データの確実な保管やデータ取り込み(一括取り込みやストリーミングでの取り込み)を担当し、クエリエンジン機能は、コンソールやコマンド等から渡された各種クエリの実行を担当するという、役割分担が可能になっています。クエリの具体例、データの取り込み、外部データソースの利用、料金例等は後述します。
BigQuery についてより理解を深めたい方は以下の記事がオススメです。
超高速でデータ分析できる!専門知識なしで扱えるGoogle BigQueryがとにかくスゴイ!
BigQuery を利用するにあたりのデータ移行の方法やリアルタイム分析の方法や気をつけるべきセキュリティ対策について理解したい方は以下の記事もあわせてご覧ください。
【意外と簡単?】オンプレミスの DWH から BigQuery へのデータ移行を徹底解説!
効率的なリアルタイム分析を実現! BigQuery を活用したレプリケーションのやり方とは?
BigQueryで考慮すべきセキュリティとその対策を一挙ご紹介!
Google Cloud(GCP)のストリーム分析がすごい!「 Pub / Sub 」や「 BigQuery 」など具体的なサービスを一挙紹介
【アプリケーションのデータ分析】FirebaseアナリティクスとBigQueryの連携方法
Cloud Spannerとは?
Cloud Spanner は、前述のデータベースポートフォリオのリレーショナルにカテゴライズされる、フルマネージドのデータベースサービスです。Google Cloud(GCP)の各リージョンにグローバルにデータを配置しつつ、トランザクションの一貫性を保ち、スケールが可能なエンタープライズ用途のサービスと位置づけられています。
同じくリレーショナルにカテゴライズされているCloud SQL は、MySQL/PostgreSQL/SQL Server のエンジンをフルマネージドで提供しますが、Cloud Spanner は、グローバルにスケールを可能にする特別なエンジンとして設計されています。
AWS クラウドでいうと、Cloud SQL はRDS に相当し、Cloud Spanner はAmazon Aurora に近いです。このため、オンプレのMySQL データベースをCloud SQL に移行するというような事例と比較すると、Cloud Spanner は、ユーザー事例が少ないサービスでもあります。銀行のオンラインバンキング、ゲーム業界のリアルタイムの大量トラフィックをさばくプラットフォーム、小売オンラインショッピング等、大規模なグローバル企業での採用事例があります。
このように、Cloud Spanner は公開情報では、「(Cloud SQL と比べ)癖がある」「移植性が低い」「高価」という評価がされやすいですが、これはSpanner が、従来のSQLニーズに対応する汎用性の高いCloud SQL とは異なり、グローバルの大量トランザクションをさばき、同時にデータの分散配置も可能にすることを優先していることから出てくる評価と考えれます。
最近では、プレビューですがPostgreSQLとの互換性をリリースしており、「癖」や「移植性」の評価を見直すため、開発者に寄り添うフェーズに入ってきているようにも見受けられます。
クエリの具体例、料金例等は後述します。
Cloud Spanner についてより理解を深めたい方は以下の記事がオススメです。
Google のリレーショナルデータベース Cloud Spanner とは?概要、特徴、メリット、活用事例まで一挙に紹介!
Cloud Spanner で性能調査をするためのポイントとは? RDBMS の一般的な観点も交えて徹底解説!
異なる DBMS から効率的に Cloud Spanner へ移行!ツールを活用したマイグレーション方法を徹底解説!
Cloud Spanner と Cloud SQLの違いを知りたい方は以下の記事もあわせてご覧ください。
BigQuery で分析するデータはどこにあるのか?
BigQuery でデータ分析をするためには、主に、BigQuery のストレージにデータを取り込む方法と、BigQuery にデータを取り込まず外部データソースに直接クエリする方法があげられます。
下図左は、BigQuery のストレージにデータを取り込む方式です。データレイクと位置付けたGoogle Cloud Strage (GCS)からファイルを一括で取り込んだり、ストリーミング、データ転送等、様々な方式があります。下図右は、一般公開/共有設定済みのデータセットや外部データソースに対し、BigQueryがクエリを実行し分析を行う方式です。
外部データソースに対しては、「連携クエリ」とよばれる、クエリを外部データベースに送信し結果を一時テーブルとして返す方法を使います。(2022/04時点で、連携クエリに対応しているのは、Cloud SQL とCloud Spanner の2つです)外部データソース利用については、連携クエリのほかに「外部テーブル」を使用する方法もありますが、こちらは後述します。
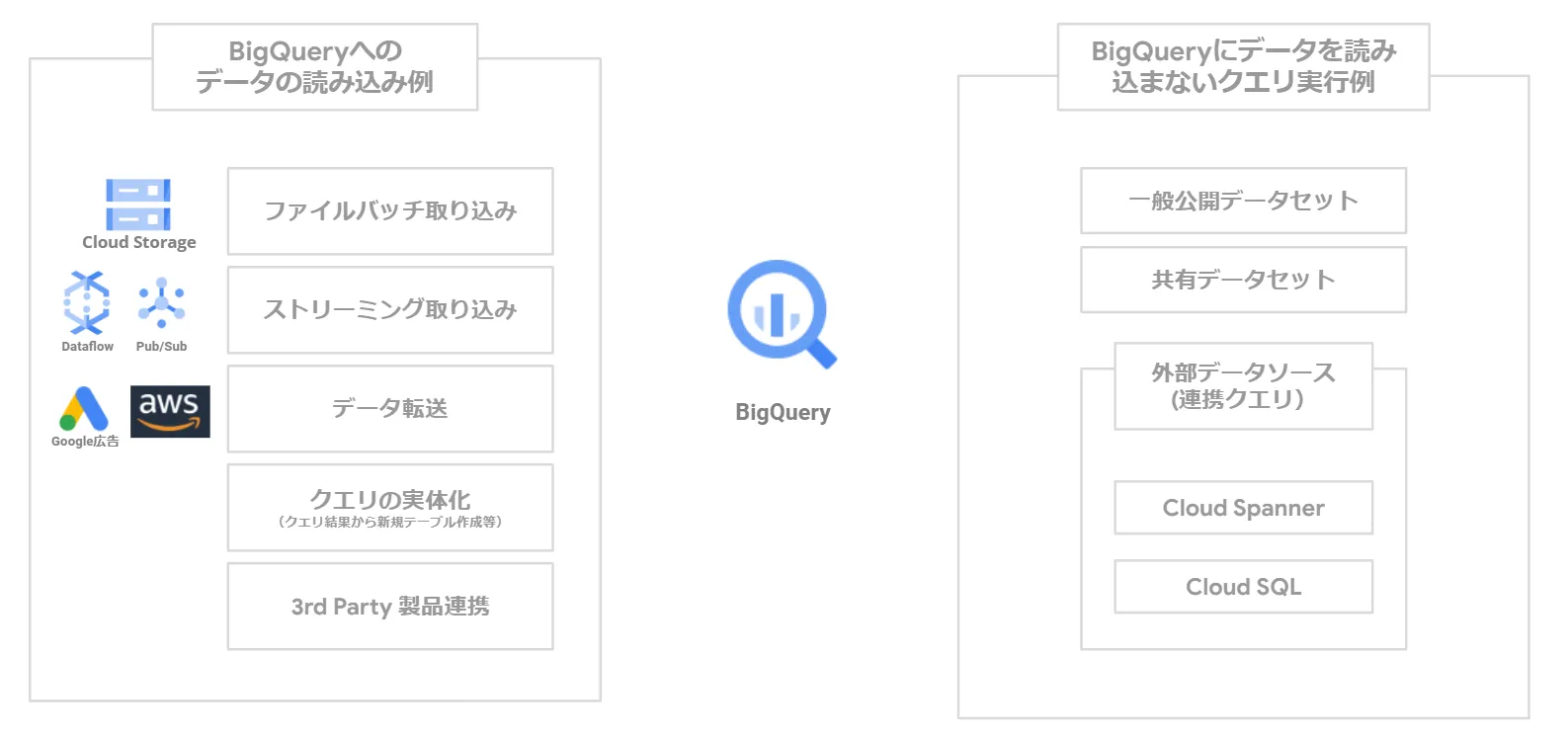
BigQuery にデータを取り込む方法
本ブログのテーマは、BigQuery から外部データソース(Cloud Spanner)への直接アクセスですが、本テーマの方式との対比のため、BigQuery ストレージにデータを取り込む方式について、簡単にピックアップして紹介します。
バッチ取り込み
リアルタイムで処理する必要のない大容量のデータセットをBigQuery のバッチ読み込みジョブを使って、取り込みます。(圧縮ファイルも対応)
Google Cloud(GCP)は、Google Cloud Strage (GCS)にサポート形式のファイル(json、csv等)を配置しデータレイクとすることを推奨しています。
データ転送
外部ストレージ(AWS のS3 やデータウェアハウスのRedshift、Teradata 等)からの転送をフルマネージドで実現します。分析はBigQuery を使いたいが、データレイクがすでに他のストレージに構築済みの場合に採用される方式です。
その他、ストリーミング取り込み、クエリ実体化、3rd パーティ連携等の取り込み方式がありますが、本ブログでは割愛します。
BigQuery の外部に保存されたデータを利用する方法
事前の前置きが長くなりましたが、本ブログのテーマです。まず、自身が管理するBigQuery から他のBigQuery が一般公開、共有しているデータにアクセスする場合、自身のストレージを使うことなく、データを利用できます。
次に、BigQuery がサポートしている外部データソースにアクセスする場合ですが、2つの方式があるのでご注意ください。
1つ目は、BigQuery に外部テーブルを作成する方式で、Bigtable、Google Cloud Strage (GCS)、Google ドライブが対応しています。この方式は、データの実体は外部ソースにありますが、テーブルのスキーマ等の属性情報(メタデータ)は、BigQuery のストレージに保存します。BigQuery は外部テーブルに対してクエリを実行し、他のテーブルと結合が可能です。
Bigtableに関しては以下の記事で詳しく解説しておりますので、あわせてご覧ください。
Google Cloud(GCP) のCloud Bigtableとは?コスパ最強のデータベース・ストレージサービスを徹底解説!
2つ目は、前述しましたが、BigQuery からAPI経由で外部データベースに接続する「連携クエリ」という方式で、これは、Cloud SQL、Cloud Spanner が対応しています。これにより、データやコピーを行わずに、Cloud Spanner に存在するデータをリアルタイムで取得できます。
以降、この「連携クエリ」方式をクローズアップして、メリット、デメリット、実機画面を解説していきます。
BigQuery からCloud Spanner のデータにクエリを実行するメリット・デメリット
ここで、BigQuery からCloud Spanner のデータにクエリを実行する方法のメリット、デメリットについて、改めて整理します。
メリット
- 連携クエリにより直接クエリを実行可能(リアルタイム性が高い)
- BigQuery へのデータのコピーや移動が不要(プロセス省略、時間・費用コストの節約)
- EXTERNAL_QUERY関数経由で、Cloud Spanner ネイティブのSQL を実行できる(クエリはCloud Spanner で実行されるため、Cloud Spanner 内と同じSQL 機能やオプティマイザが利用可能)
デメリット
- BigQuery ストレージへのクエリと比較して、クエリ速度が落ちる可能性がある(外部データソースのインフラ性能に依存)
- 連携クエリのサポート対象が少ない(Cloud Spanner の他は、Cloud SQL)
- 負荷の高いクエリによる分析を行いたい場合、BigQuery へのデータコピーが必要(ただし、コピープロセス構築は不要で、create tabele as select による取り込みが可能)
デメリットをいくつか記載していますが、リアルタイム分析を実現するためには、データコピー移動プロセスを省略してクエリを発行できる本方式の有用性は、非常に高いものではないでしょうか?
実際にCloud Spanner のデータにクエリを実行してみよう
実施の実機操作について解説します。まず、Google Cloud コンソールにログイン後、Cloud Spanner の事前準備を行います。(今回は疎通確認のため、一連の作業をadmin 権限で実施していますが、本番運用時は、クエリの実行権限等を整理する必要があります)Cloud Spanner のトップページからインスタンスを作成します。
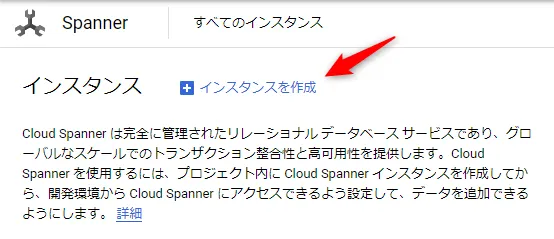
疎通確認のため、1ノードの最小構成で作成します。(コンピューティングの費用が表示されるのでわかりやすいです。本番運用では「1年確約利用」は必須になりそうですね)
インスタンス名は、「spanner-testdb」としました。
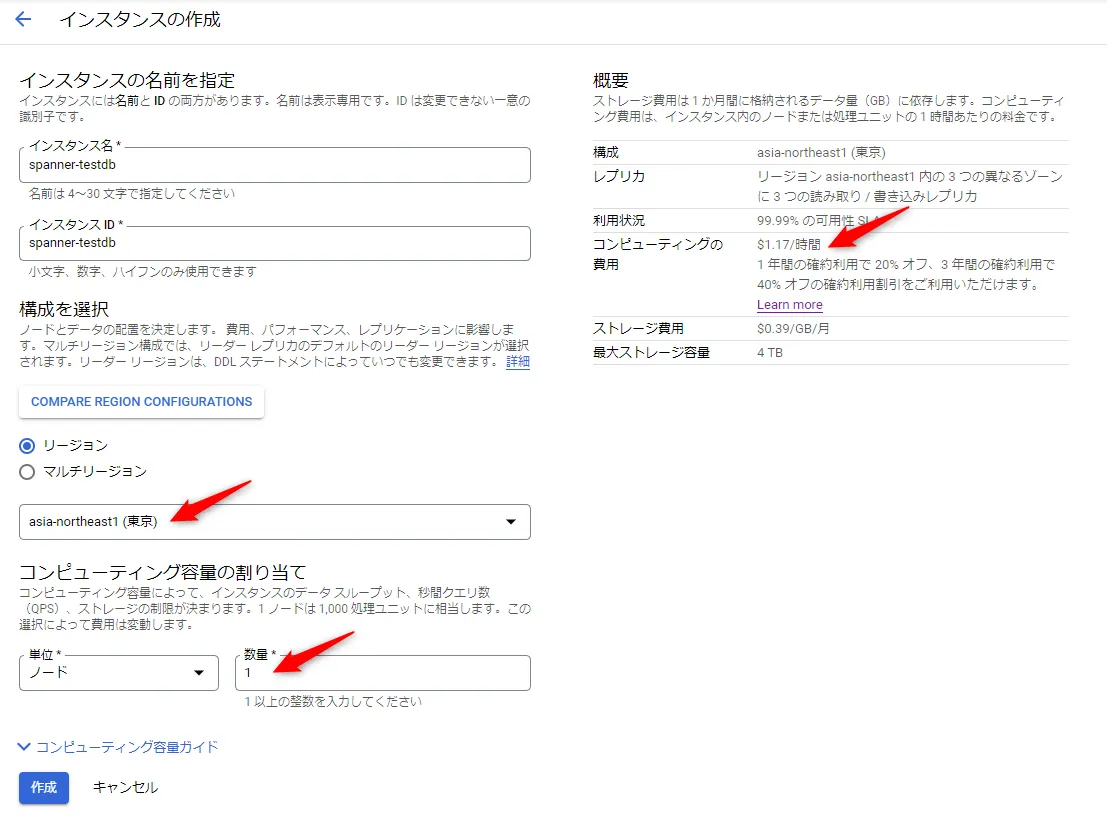
インスタンス作成が完了したら、インスタンス内にデータベースを作成します。データベース名は、「testdb」としました。(前述した通り、PostgreSQLでのデータベース言語が選択可能ですが、ここではデフォルト指定のGoogle 標準SQL としています)
「testdb」が作成されました。続いてテーブルを作成します。
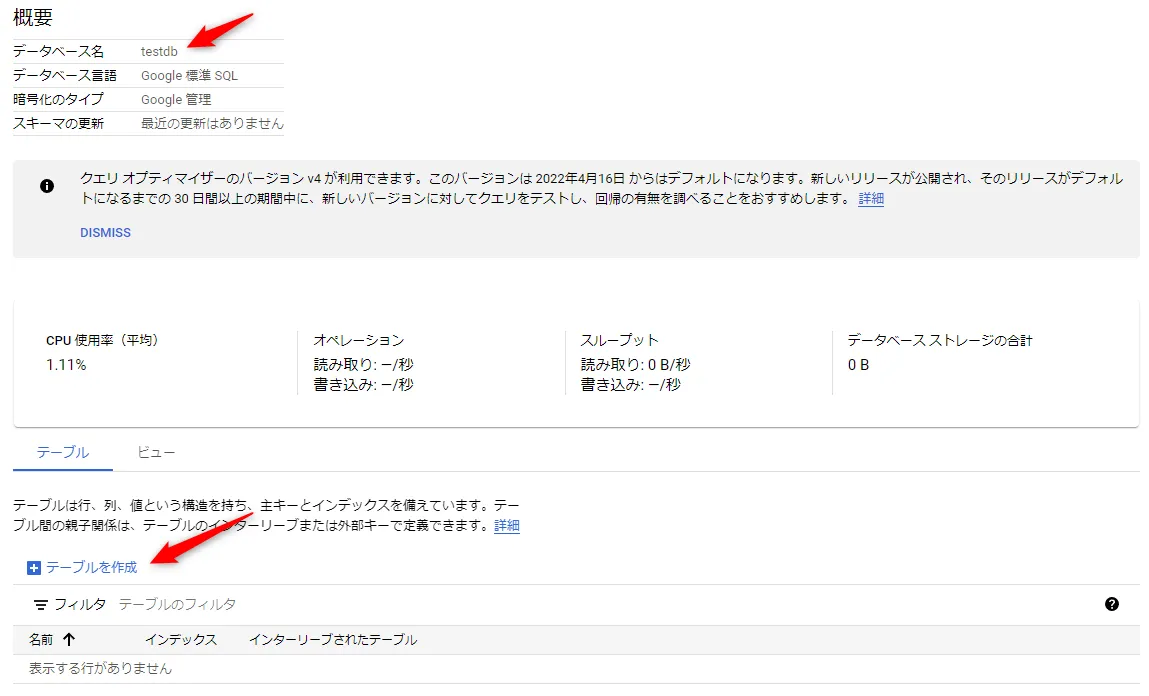
Cloud Spanner に作成されるデータは、頻繁な更新がかかるものがほとんどのため、ここでは、シンプルな注文テーブル「orders」を作成します。(下記DDL参照)
CREATE TABLE orders (
customer_id INT64 NOT NULL,
customer_name STRING(1024),
order_date DATE,
) PRIMARY KEY(customer_id);
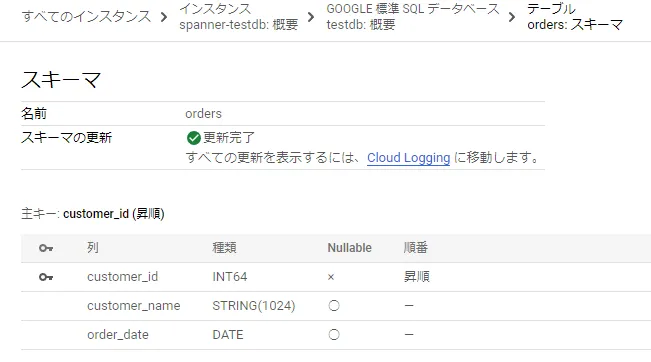
「orders」テーブルが作成されました。
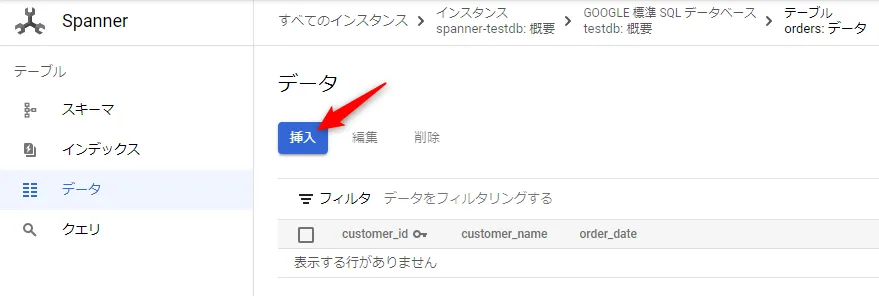
続いてテーブルにテストデータを1件をインサートします。Spanner ナビゲーションペインの「データ」を選び、挿入ボタンをクリックします。
サンプルのINCERT文が表示されるため、テーブル作成時に定義したカラム名と任意の値を入力し、実行ボタンをクリックすると、1行のデータが挿入されます。
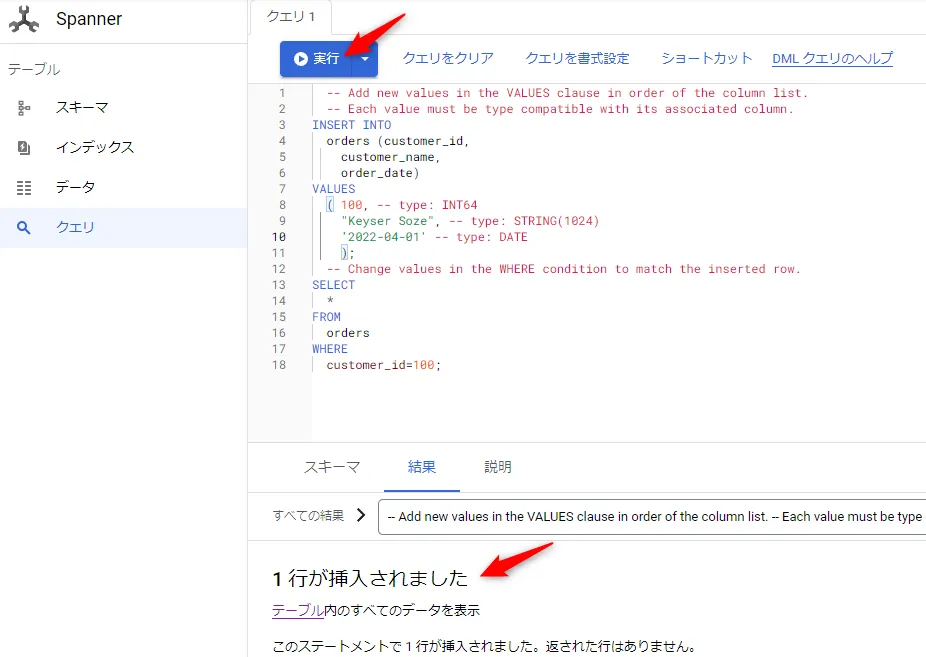
インサートしたデータを「select * from orders」クエリで確認します。先ほど作成した1件のレコードがヒットしました。
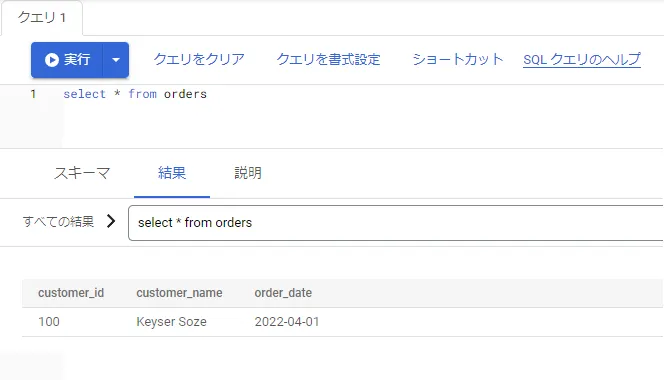
これでCloud Spanner の事前準備は終わりです。
次にBigQuery の事前準備を行います。
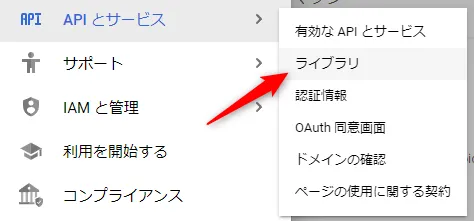
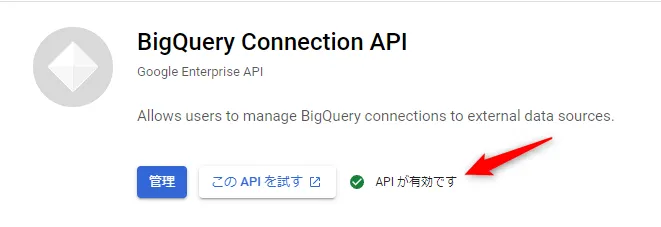
ナビゲーションペインのAPI ライブラリから、BigQuery Connection API が有効であることを確認します。(有効でない場合、[有効にする] ボタンをクリックします)
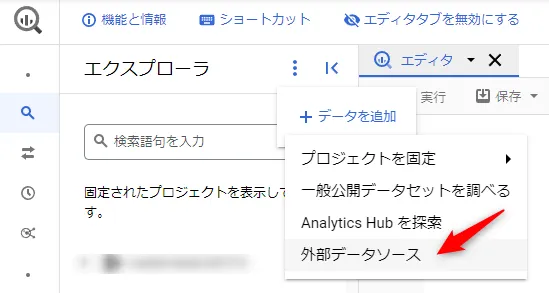
BigQuery のトップページの「データの追加」から「外部データソース」をクリックします。
外部データソースの設定値は、下記の通りです。接続IDは任意の値で問題ありません。Database name の設定は、下記形式が決まっていますので、黄色強調部分の「PROJECT_ID」「Cloud Spanner のインスタンス名」「Cloud Spanner のデータベース名」を正確に入力してください。
"projects/PROJECT_ID/instances/INSTANCE/databases/DATABASE"
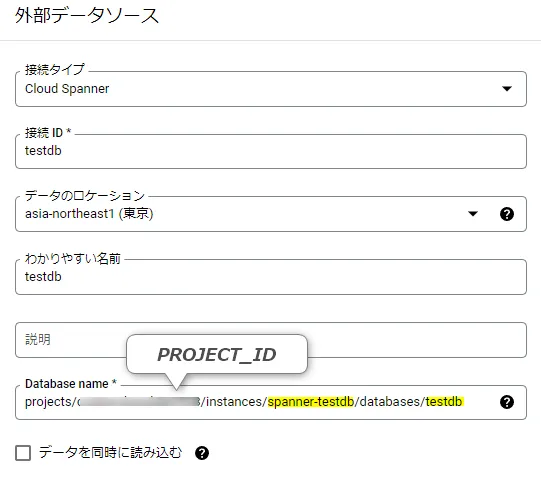
外部データソース作成が成功すると、下記の接続情報が確認できます。接続IDに表示されている値は、この後のクエリに利用します。
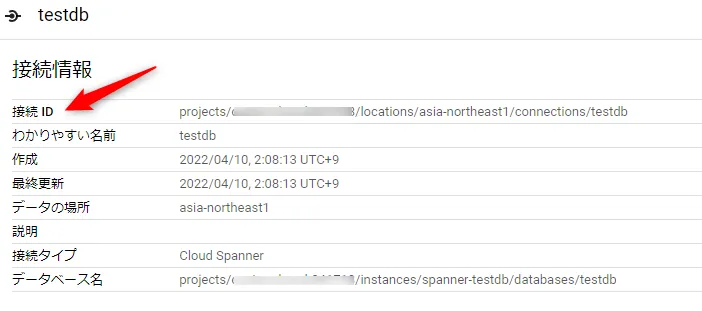
これでBigQuery の事前準備は終わりです。
それでは、BigQuery からCloud Spanner に疎通確認を行います。BigQuery のナビゲーションペインに先ほど設定した外部接続が表示されていますので、クエリをクリックすると、黄色強調部分のように、Cloud Spanner へのクエリフォーマットが表示されます。このフォーマットが外部データソースへのクエリの基本形です。
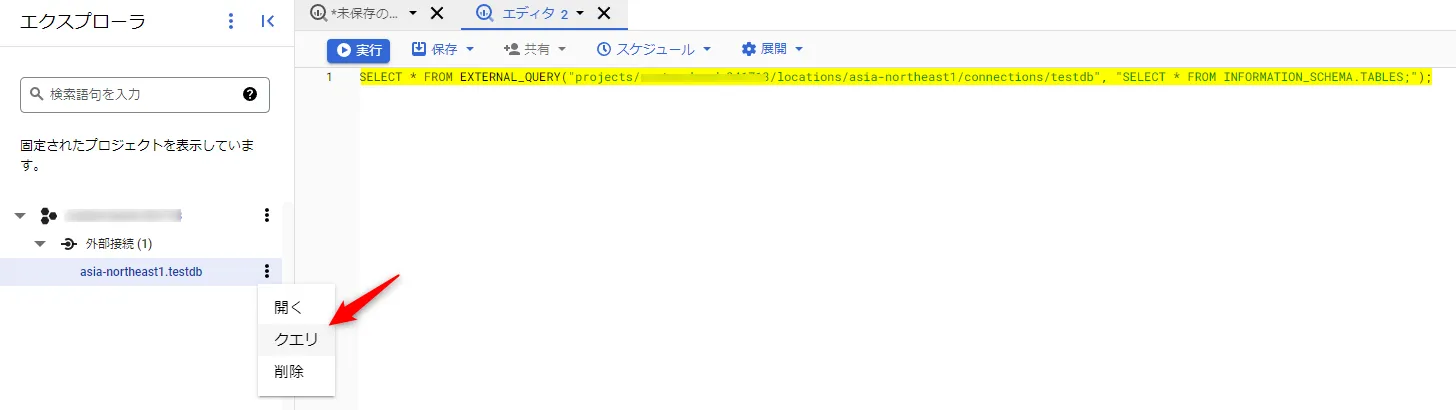
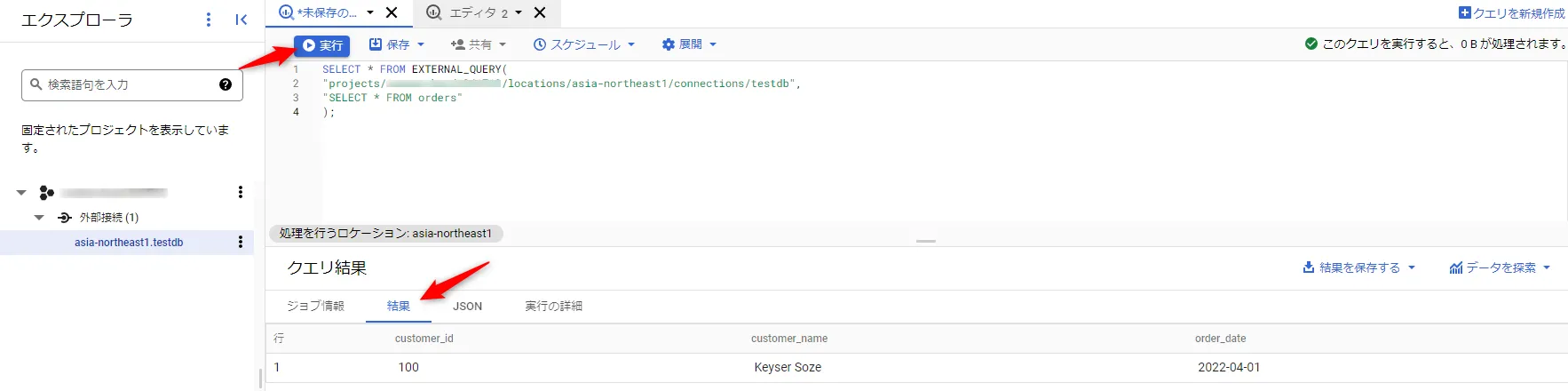
こちらを下記のように接続IDと「select * from orders」を外部クエリに設定し、実行ボタンをクリックすると、Cloud Spanner にクエリが送信され結果が表示されます。
事前準備が問題なければ、このようにCloud Spanner のデータを簡単に取得できます。
※検証の場合は、課金を止めるため、Cloud Spanner のインスタンスを確実に削除しましょう。
料金例
BigQuery 料金例
BigQuery の料金体系は、主に「分析料金」、「ストレージ料金」、「データ取り込み/抽出」があります。この内、「ストレージ料金」は、BigQuery ストレージにデータを保管する費用をさし、「データの取り込み/抽出」については、バッチによる取り込みやエクスポート等、特定オペレーションのデータ移動に対する費用をさします。
「分析料金」については、次の2つのモデルがあります。いずれかのモデルを選択することも、ニーズに応じて併用することも可能です。
- オンデマンド料金
この料金モデルでは、各クエリによって処理されたバイト数に基づいて課金されます。処理されるクエリデータは毎月 1 TB まで無料です。 -
定額料金
この料金モデルでは、仮想 CPU であるスロットを購入します。スロットを購入すると、クエリの実行に使用できる専用の処理容量を購入したことになります。
月間プラン(30日分)、年間プラン(365日分)、Flex Slots(60秒分購入しその後、スロットのキャンセルが可能になるスポット利用)
概算見積もりにおいては、「分析料金」「ストレージ料金」を押さえておくのがよいでしょう。また、分析が定期的実行であったり、一定量の分析を継続するニーズがある場合は、定額料金をご検討ください。
Cloud Spanner 料金例
Cloud Spanner の料金体系は、主に「インスタンスのコンピューティング容量(ノード数単位)」「ストレージ料金(データベース領域、バックアップ領域)」「Cloud Spanner から外に出ていくデータトラフィック量」があります。この内、「ストレージ料金」は、Cloud Spanner データベースを保管するデータ量、バックアップ領域に保管するデータ量に対して課金されます。
「Cloud Spanner から外に出ていくデータトラフィック量」は、外向きのトラフィックに対する課金のみで、Cloud Spanner に入る内向きのトラフィックには課金されません。「インスタンスのコンピューティング容量(ノード数単位)」は、1ノード(1,000 処理ユニットとも表現される)に対して1時間単位で課金が発生します。
Google Cloud(GCP) の中でも、1時間あたり1USドル前後と比較的高額ですが、確約利用割引(CUD)という1年以上継続的に使用することと引き換えに、20%~40%の割引が利用できます。本番環境の運用では、確約利用割引は多くのケースで利用必須となると考えられます。
おわりに
リアルタイム分析を目的として、BigQuery からCloud Spanner に直接クエリを実行する方式、メリットデメリット、具体的な手順を解説しました。データ分析は分析対象となるデータソースが複数あるケースや、BigQuery へのデータ移動やコピー中に更新されていくCloud Spanner のようなデータベースも多いと思います。
データコピーや移動のプロセス構築の省略や、最新のデータからのクエリ結果取得を通じて、ニーズの高まっていくリアルタイム分析に注力できる環境を構築していきましょう!
弊社トップゲートでは、Google Cloud (GCP) 利用料3%OFFや支払代行手数料無料、請求書払い可能などGoogle Cloud (GCP)をお得に便利に利用できます。さらに専門的な知見を活かし、
- Google Cloud (GCP)支払い代行
- システム構築からアプリケーション開発
- Google Cloud (GCP)運用サポート
- Google Cloud (GCP)に関する技術サポート、コンサルティング
など幅広くあなたのビジネスを加速させるためにサポートをワンストップで対応することが可能です。
Google Workspace(旧G Suite)に関しても、実績に裏付けられた技術力やさまざまな導入支援実績があります。あなたの状況に最適な利用方法の提案から運用のサポートまでのあなたに寄り添ったサポートを実現します!
Google Cloud (GCP)、またはGoogle Workspace(旧G Suite)の導入をご検討をされている方はお気軽にお問い合わせください。
お問合せはこちら
メール登録者数3万件!TOPGATE MAGAZINE大好評配信中!
Google Cloud(GCP)、Google Workspace(旧G Suite) 、TOPGATEの最新情報が満載!